map和sync.Map实现原理,知道上面什么下用什么类型的map 。
map的实现原理
hashmap通常实现方式
通常有2种实现方式
-
Hashmap实现之开放寻址法
k:v , 对k进行hash后, 放到某个位置,如果位置占用就延到空的位置放入,查找也是从位置开始找,没找到向后找。
-
Hashmap实现之拉链法 (go 采用这种方式实现)
hash碰撞的 都放在一个桶(也叫槽)(bucket ,是指针)
1// runtime/map.go
2// A header for a Go map.
3type hmap struct {
4 // Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go.
5 // Make sure this stays in sync with the compiler's definition.
6 count int // # live cells == size of map. Must be first (used by len() builtin) //键值对数
7 flags uint8
8 B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items) // 8个桶这里就是3 4个桶就是2
9 noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
10 hash0 uint32 // hash seed //hash算法的种子 or 计算 key 的哈希的时候会传入哈希函数
11
12 // bmap数组 Bucket 数组 个数为 2^B 个 。
13 buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
14
15 // 扩容的时候用
16 // 等量扩容的时候,buckets 长度和 oldbuckets 相等
17 // 双倍扩容的时候,buckets 长度会是 oldbuckets 的两倍
18 oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
19
20 // 指示扩容进度,小于此地址的 buckets 迁移完成
21 nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
22
23 extra *mapextra // optional fields //溢出桶的信息
24}
1// A bucket for a Go map.
2type bmap struct {
3 // tophash generally contains the top byte of the hash value
4 // for each key in this bucket. If tophash[0] < minTopHash,
5 // tophash[0] is a bucket evacuation state instead.
6 tophash [bucketCnt]uint8 //key hash后的高8位值 ,bucketCnt = 常量 8
7 // Followed by bucketCnt keys and then bucketCnt elems.
8 // NOTE: packing all the keys together and then all the elems together makes the
9 // code a bit more complicated than alternating key/elem/key/elem/... but it allows
10
11 //编译的时候放把 key和 value 放进去
12
13 // us to eliminate padding which would be needed for, e.g., map[int64]int8.
14
15 //溢出指针
16 // Followed by an overflow pointer.
17}
18
19
20// 编译后会变这样。
21// 这个结构体会在运行后被动态重建,重建后的样子: ,因为key,value 类型是动态的。
22type bmap struct {
23topbits [8]uint8 //topbits: 是存储高八位的hash用于定位key在桶中的位置
24keys [8]keytype //keys: 所有的key 存放在一起 values
25values [8]valuetype //values: 所有的value 存放在一起
26pad uintptr
27// bmap中最多放8个key8个value 多出的 用溢出指针,放到另外的bmap中
28overflow uintptr //overflow: 下一个桶的指针 这里一个桶只能存八个元素,就会存在overlow 中
29}
30//一个结构中只能放八个元素,超过八个则通过overflow连接到一个新的bmap 结构中超过8个会极大影响性能。
31// extra 会存溢出桶的信息, 下一个溢出桶的 指针
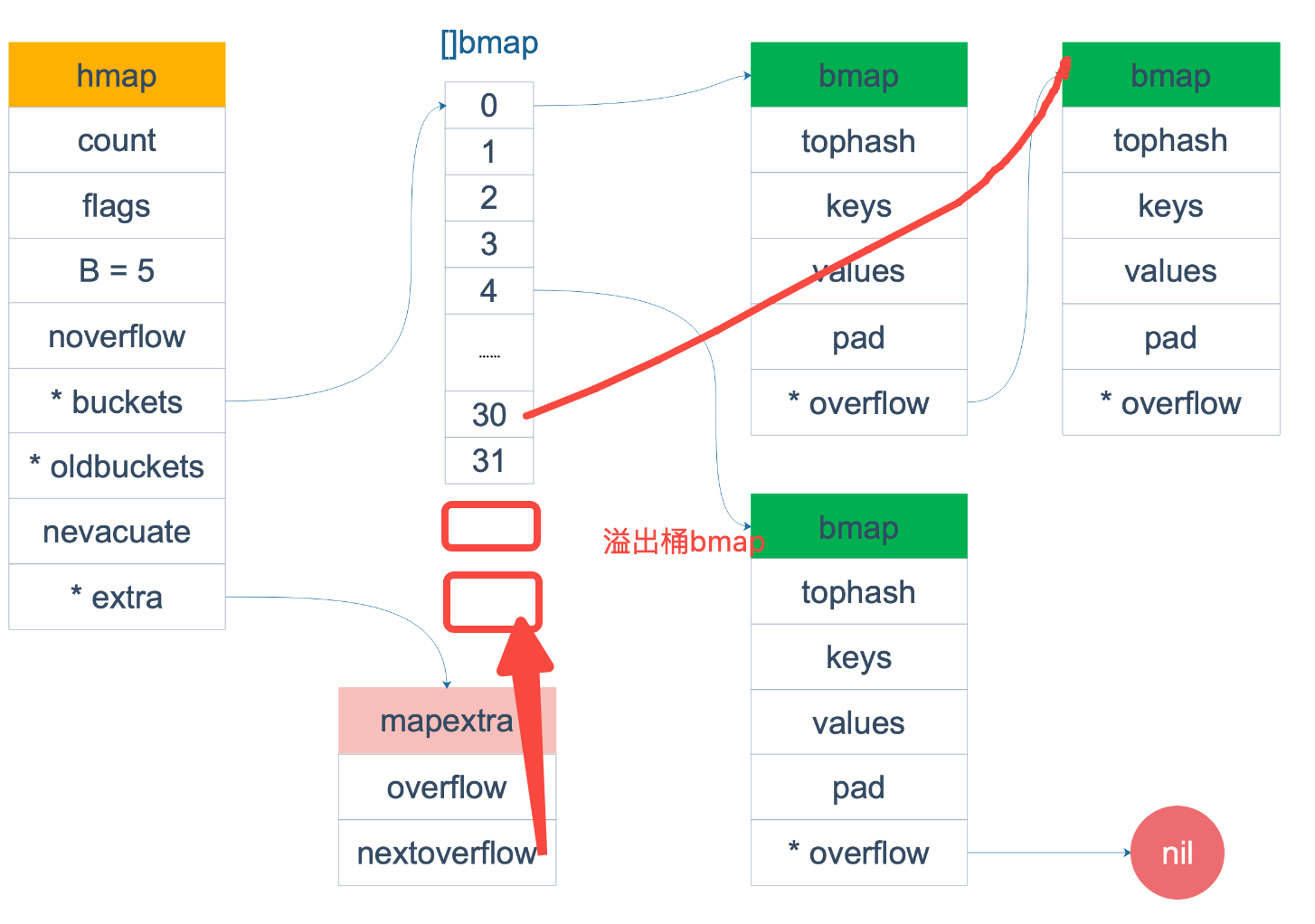
make 初始化
如hmap的 B是3 那么就是创建8个桶 。 那么就是只有存放 8 * 8(一个桶8个元素) = 64 个元素了, 它额外会创建一些溢出桶的。
nextOverflow 可用的溢出桶指针,指向bmap中的位置。
字面量初始化
汇编的时候 就是 创建一个空map ,然后取简单赋值(<=25个元素) 或者 循环赋值 大于25个元素,k数组,v数组 循环写到map里)
map的访问
- 先是计算桶号,再在桶中找对应的数据
- 每一个桶中存储键哈希的前8位
- 桶超出 bucketCnt 个数据(8个),就会存储到溢出桶去
桶的定位,计算桶号
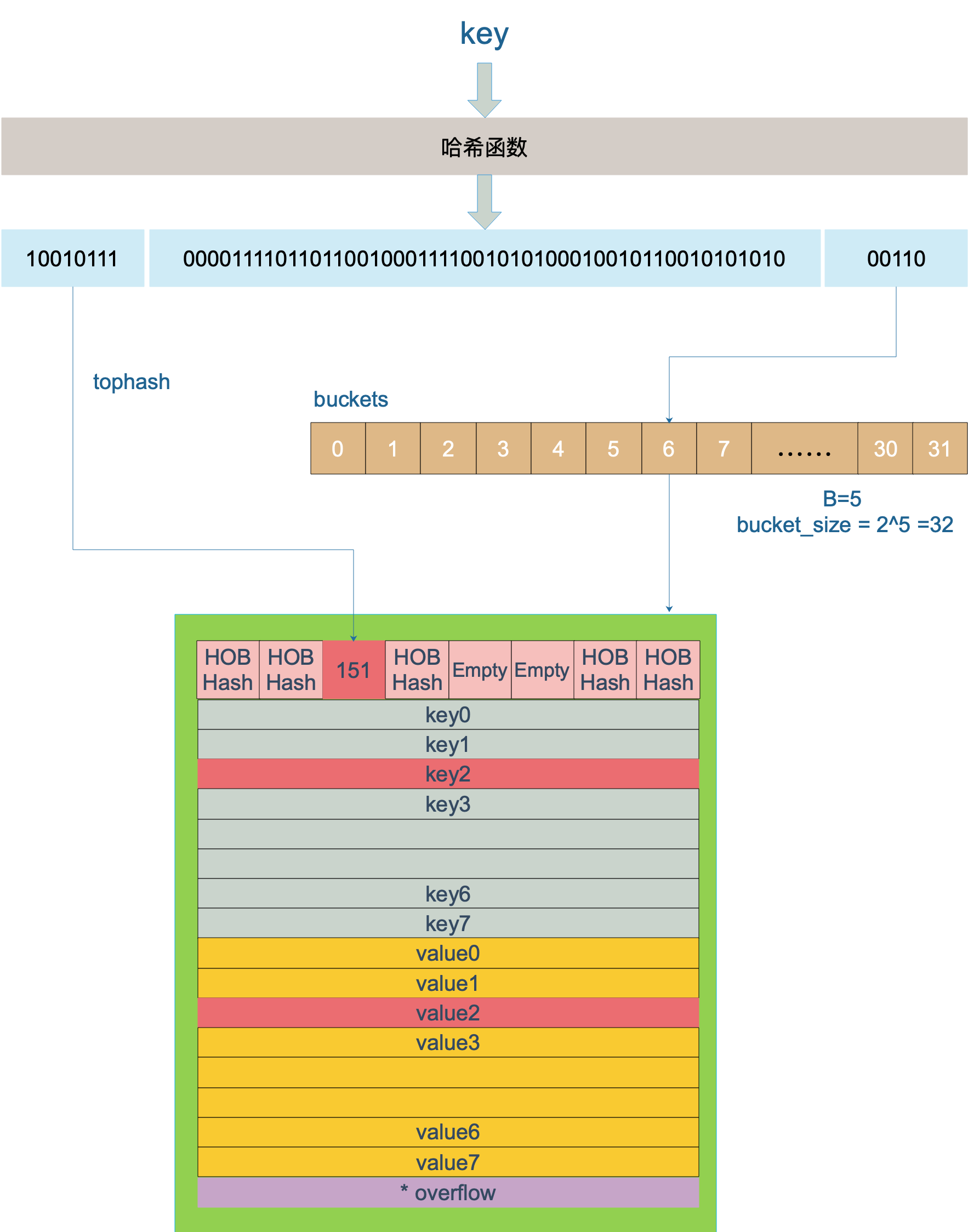
确定是哪个bmap
key +hash0函数后 得到二进制数值
B=5 取二进制的后5位 ,决定桶号 00110=6 那么bucket取6号桶
桶中的位置确定
上图中,假定 B = 5,所以 bucket 总数就是 2^5 = 32。首先计算出待查找 key 的哈希,使用低 5 位 00110,找到对应的 6 号 bucket,使用高 8 位 10010111,对应十进制 151,在 6 号 bucket 中寻找 tophash 值(HOB hash)为 151 的 key,找到了 2 号槽位,这样整个查找过程就结束了。
如果在 bucket 中没找到,并且 overflow 不为空,还要继续去 overflow bucket 中寻找,直到找到或是所有的 key 槽位都找遍了,包括所有的 overflow bucket。
map 的写入
没有就写入, 有就修改value 。 查找方式 和map 的访问一致
map 的扩容
-
溢出桶太多会导致性能下降(变链表了)
-
runtime.mapassign()可能会触发扩容的情况
- 装载因子超过6.5 (平均每个槽大于6.5个key)
- 使用了太多溢出桶 (溢出桶大于普通桶数量)
-
可以是等量扩容 (可能空洞太多了,整理一下,如删除数据) ,也可以是翻倍扩容( 溢出桶太多了,普通桶数翻倍)
创建一组新的桶
oldbuckets 指向老的桶数组
buckers 指向新的桶数组
更新新桶的extra 结构体溢出信息
迁移数据 将数据从旧桶渐进式 迁移到新桶 ,每次操作一个旧桶时,将旧桶数据迁移到新桶,读取时不进行迁移,只判断读取新桶还是旧桶
所有旧桶迁移完成后,就回收 oldbuckets ,释放空间
如 好比之前B=2 ,那算出来是在 xxx00110 , 10是2号bmap中,扩容后B=3 ,那么数据就会在 老桶的 2号桶和 新桶的6号桶中找。
map总结
map是并发不安全的
map扩容的时候, a协程读老桶, b协程在写入,驱逐到新桶 。
map并发解决方案 加mutex, 这个性能不高 ,只能有一个协成对这个map 操作。
sync.Map 实现原理
正常读写在read map中完成
amended=false 表示 dirty和read一致
*entry 是个指针 指向具体的空间
1type Map struct {
2 // 加锁作用,保护 dirty 字段
3 mu Mutex
4 // 只读的数据,实际数据类型为 readOnly
5 read atomic.Value
6 // 最新写入的数据
7 dirty map[interface{}]*entry
8 // 计数器,每次需要读 dirty 则 +1
9 misses int
10}
11
12type readOnly struct {
13// 内建 map
14m map[interface{}]*entry
15// 表示 dirty 里存在 read 里没有的 key,通过该字段决定是否加锁读 dirty
16amended bool
17}
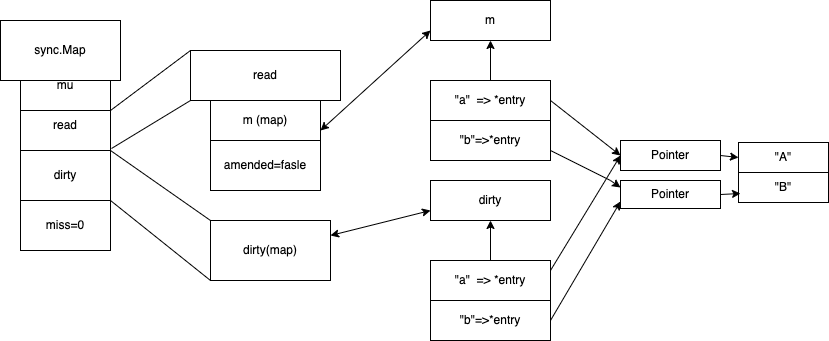
sync.Map追加
先找read map 是否有值 没有加锁操作dirty map 。
追加是追加到 dirty 这个map的, read的amended 改成true ,操作dirty map 要加上锁
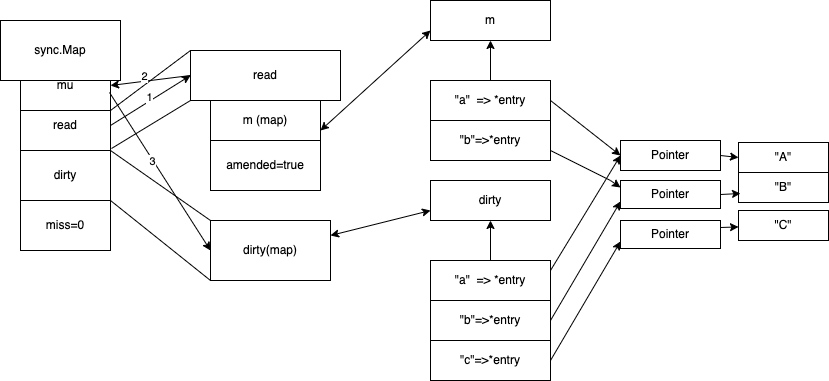
Sync.Map 追求后读写
当访问c 的时候 先从read map 读 没读到 从 dirty 去读一遍 ,并记录misses +1 ,当misses的值= len(dirty) 的时候, 进行dirty提升
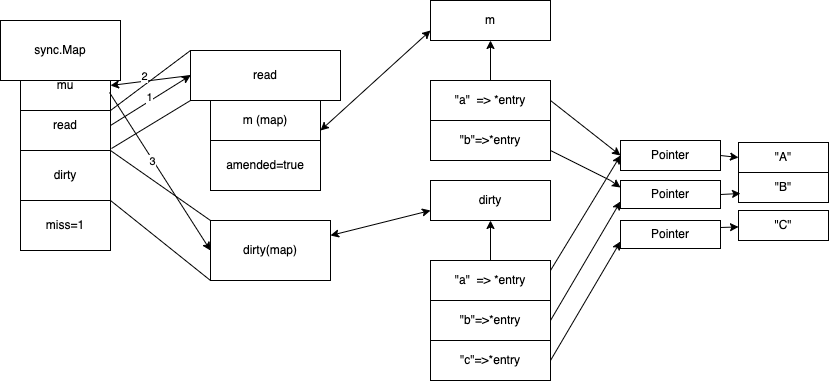
dirty 提升
当misses 当值=len(diry) ,进行dirty 提升,用dirty map 去替换read map ,dirty map 改成nil, 此时会用到写时复制 ,下次修改到时候, dirty 会等于 之前 read map 。
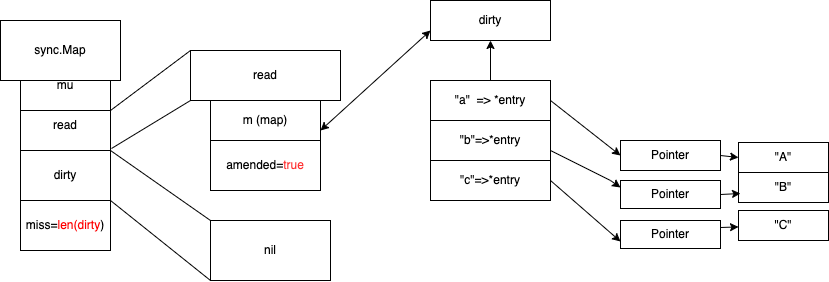
写时复制
copy on write 写时复制 , dirty 会等于 之前 read map 。
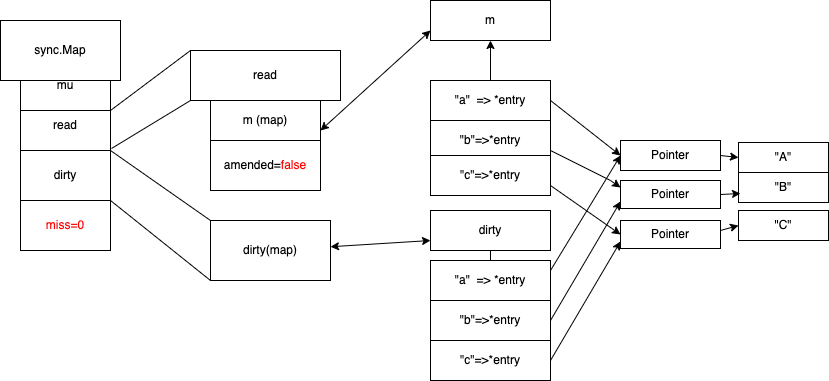
正常删除(amended=false)
正常删除 (misses =0 ,amended=false 的时候),操作read map 直接指向 nil
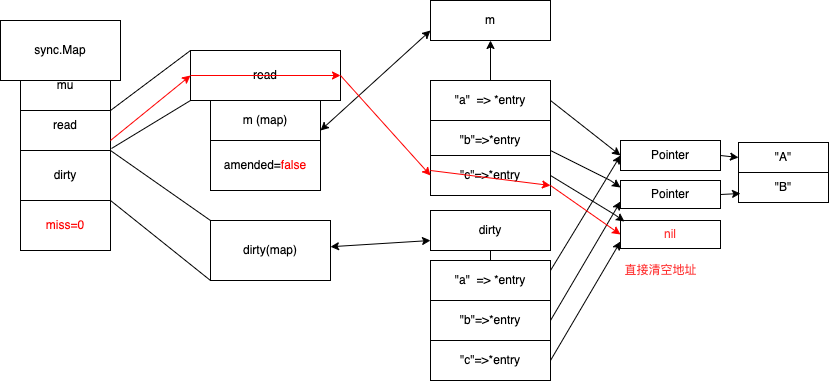
追加后删(amended=true)
追加后删除(amended=true) , 然后立马进行提升dirty
先从read map 去删除,没找到,就加锁 去 dirty map 去删除 ,标记nil
进行dirty 提升
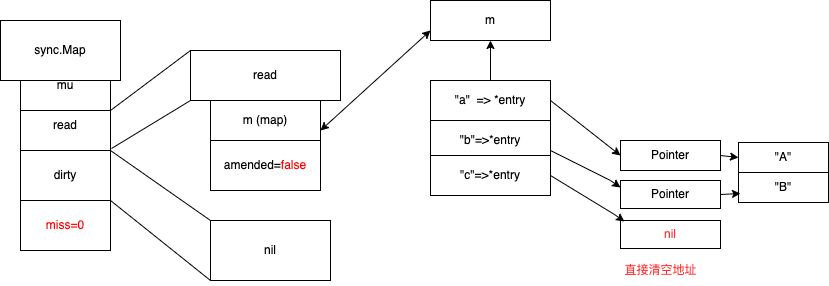
写时复制,c元素标记为expunged(删除标记)
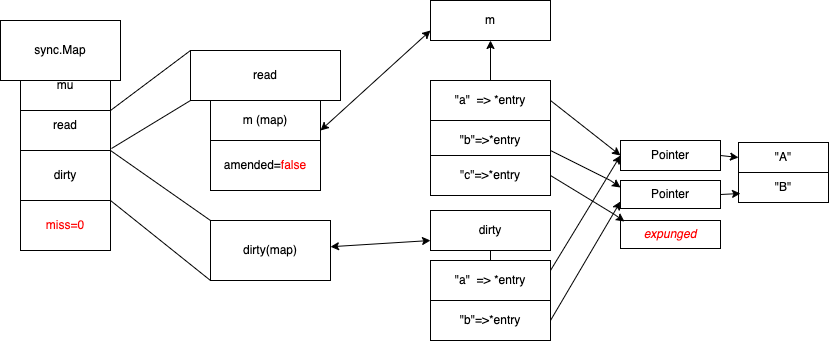
sync.Map总结
map在扩容时会有并发问题
sync.Map使用了两个map, 分离了扩容问题
不会引发扩容的操作(查,改) 使用read map, 没找到则,加锁操作dirty map
可能引发扩容的操作(新增)使用dirty map,使用dirty map都要加锁
sync.Map如果是 查,改多的情况 是比 普通map 加锁 性能高的, 如果都是 新增 那和普通map加锁 ,性能是 普通map 加锁性能高(经常Benchmark测试过了)。
操作dirty 都是加锁的
map 并发处理
遍历map其实就是读
遍历map 其实就是在读, 有并发问题
1package main
2
3import (
4 "sync"
5)
6
7
8func main() {
9 type m2 struct {
10 num int
11 }
12 var mu sync.RWMutex
13 var m1 = make(map[int]*m2)
14 for i := 0; i < 10000; i++ {
15 go func(num int) {
16 mu.Lock()
17 m1[num] = &m2{num: num}
18 mu.Unlock()
19 }(i)
20 }
21 //var copyMap = make(map[int]*m2)
22 //
23 //mu.RLock()
24 //for key, value := range m1 {
25 // copyMap[key] = value
26 //}
27 //mu.RUnlock()
28 for i := 0; i < 10000; i++ {
29 go func() {
30 for key, value := range m1 {
31 fmt.Println(key, value)
32 }
33 }()
34 }
35 select {}
36}
copy map 在遍历
下面代码是并发安全的
1package main
2
3import (
4 "sync"
5)
6
7func main() {
8 type m2 struct {
9 num int
10 }
11 var mu sync.RWMutex
12 var m1 = make(map[int]*m2)
13 for i := 0; i < 10000; i++ {
14 go func(num int) {
15 mu.Lock()
16 m1[num] = &m2{num: num}
17 mu.Unlock()
18 }(i)
19 }
20 var copyMap = make(map[int]*m2)
21
22 mu.RLock()
23 for key, value := range m1 {
24 copyMap[key] = value
25 }
26 mu.RUnlock()
27 for i := 0; i < 10000; i++ {
28 go func() {
29 for key, value := range copyMap {
30 fmt.Println(key, value)
31 }
32 }()
33 }
34 select{}
35}
分片加锁
其实就是把大的map ,搞成切片map, 让锁的范围减小。
下面代码是基于 map分片加锁 这个思路写的。用用户id做下标,及不用interface,不然还得转换,反射等消耗
UserCacheData 是个游戏中的用户数据结构体
1package cache
2
3// 分片加锁
4
5import (
6 "sync"
7)
8
9var ShardCount int64 = 32
10
11// ShardLockMaps A "thread" safe map of type string:Anything.
12// To avoid lock bottlenecks this map is dived to several (ShardCount) map shards.
13type ShardLockMaps struct {
14 shards []*SingleShardMap
15}
16
17// SingleShardMap A "thread" safe string to anything map.
18type SingleShardMap struct {
19 items map[int64]*UserCacheData
20 sync.RWMutex
21}
22
23// createShardLockMaps Creates a new concurrent map.
24func createShardLockMaps() ShardLockMaps {
25 slm := ShardLockMaps{
26 shards: make([]*SingleShardMap, ShardCount),
27 }
28 for i := 0; i < int(ShardCount); i++ {
29 slm.shards[i] = &SingleShardMap{items: make(map[int64]*UserCacheData)}
30 }
31 return slm
32}
33
34// NewShardLockMaps Creates a new ShardLockMaps.
35func NewShardLockMaps() ShardLockMaps {
36 return createShardLockMaps()
37}
38
39// GetShard returns shard under given key
40func (slm ShardLockMaps) GetShard(key int64) *SingleShardMap {
41 return slm.shards[key%ShardCount]
42}
43
44// Count returns the number of elements within the map.
45func (slm ShardLockMaps) Count() int {
46 count := 0
47 for i := int64(0); i < ShardCount; i++ {
48 shard := slm.shards[i]
49 shard.RLock()
50 count += len(shard.items)
51 shard.RUnlock()
52 }
53 return count
54}
55
56// Get retrieves an element from map under given key.
57func (slm ShardLockMaps) Get(key int64) (*UserCacheData, bool) {
58 if key <= 0 {
59 return nil, false
60 }
61 shard := slm.GetShard(key)
62 shard.RLock()
63 val, ok := shard.items[key]
64 shard.RUnlock()
65 return val, ok
66}
67
68// Set Sets the given value under the specified key.
69func (slm ShardLockMaps) Set(userData *UserCacheData) {
70 if userData == nil {
71 return
72 }
73 shard := slm.GetShard(userData.UserId)
74 shard.Lock()
75 shard.items[userData.UserId] = userData
76 shard.Unlock()
77}
78
79// Remove removes an element from the map.
80func (slm ShardLockMaps) Remove(key int64) {
81 if key <= 0 {
82 return
83 }
84 shard := slm.GetShard(key)
85 shard.Lock()
86 delete(shard.items, key)
87 shard.Unlock()
88}
89
90// IsEmpty checks if map is empty.
91func (slm ShardLockMaps) IsEmpty() bool {
92 return slm.Count() == 0
93}
94
95// Keys returns all keys as []int64
96func (slm ShardLockMaps) Keys() []int64 {
97 count := slm.Count()
98 ch := make(chan int64, count)
99 go func() {
100 wg := sync.WaitGroup{}
101 wg.Add(int(ShardCount))
102 for _, shard := range slm.shards {
103 go func(shard *SingleShardMap) {
104 shard.RLock()
105 for key := range shard.items {
106 ch <- key
107 }
108 shard.RUnlock()
109 wg.Done()
110 }(shard)
111 }
112 wg.Wait()
113 close(ch)
114 }()
115
116 keys := make([]int64, 0, count)
117 for k := range ch {
118 keys = append(keys, k)
119 }
120 return keys
121}
122
123// IterCb Iterator callback,called for every key,value found in maps.
124// RLock is held for all calls for a given shard
125// therefore callback sess consistent view of a shard,
126// but not across the shards
127type IterCb func(key int64, v *UserCacheData)
128
129// IterCb Callback based iterator, cheapest way to read
130// all elements in a map.
131func (slm ShardLockMaps) IterCb(fn IterCb) {
132 for idx := range slm.shards {
133 shard := slm.shards[idx]
134 shard.RLock()
135 for key, value := range shard.items {
136 fn(key, value)
137 }
138 shard.RUnlock()
139 }
140}