golang基础汇总(一), 对变量、常量、操作符、分支控制、数组、切片,map、指针的使用详解。
基础
变量
变量是几乎所有编程语言中最基本的组成元素。从本质上说,变量相当于是对一块数据存储空间的命名,程序可以通过定义一个变量来申请一块数据存储空间,之后可以通过引用变量名来使用这块存储空间。
变量存储:
等号 左边的变量,代表 变量所指向的内存空间。 (写)
等号 右边的变量,代表 变量内存空间存储的数据值。(读)
变量声明与作用域
- 变量声明
1var a int = 10
2var a = 10 //编译器,类型推导出a的类型
3 a :=10 //函数内使用 ,等价于 var a int ; a=10
- 声明多个变量
1var (
2 v1 int
3 v2 string
4)
- 变量赋值与多重赋值
1var v1 int
2var i int
3var j int
4v1=10 //变量
5i,j=j,i //多重赋值
- 匿名变量
1 func getName() (firstName,lastname, nickName string) {
2 return "","nonfu", "crmao"
3 }
4 //_为逆名变量,忽略不接收的作用
5 _,_, nickName := getName()
- 变量作用域
1package main
2import "fmt"
3var a string //声明变量
4var b int //全局变量
5var c bool
6//省略多个var关键字,写成一个
7var (
8 d string = "ddd"
9 e =3
10)
11// 简写 ,但是这种写法这能写在函数内
12func variableShort(){
13 a,b,c :=1,true,"string_c"
14 fmt.Printf("%v,%v,%v\n",a,b,c)
15}
16//类型推导
17func variableTuiduan(){
18 var a = "abc"
19 fmt.Printf(" a的类型是%T\n",a) // a的类型是string
20}
21
22func getName() (a, b string) {
23 return "nonfu", "crmao"
24}
25func main() {
26 fmt.Println("hello world")
27 fmt.Println(a,b,c)
28 fmt.Printf("%q,%d,%v\n",a,b,c) //"",0,false 有初始值
29 variableTuiduan()
30 variableShort()
31 fmt.Println(d,e)
32 //_为逆名变量,忽略不接收的作用
33 _, nickName := getName()
34 fmt.Println(nickName)
35}
占位符的使用
1package main
2
3import "fmt"
4
5func zhanwei() {
6 a:=10//int
7 fmt.Printf("%d\n",a) //%d 整数
8 //var b float64 =10
9 b:=10.0//float64
10 fmt.Printf("%f\n",b) //%f 浮点数
11 var c bool =true
12 fmt.Printf("%t\n",c) //%t bool
13 var d byte ='A'
14 fmt.Printf("%c\n",d) //%c 字符
15 var e string ="hello"
16 fmt.Printf("%s\n",e) //%s 字符串
17 fmt.Printf("%p\n",&a)
18
19 //%T 打印变量对应的数据类型
20 fmt.Printf("%T\n",a) //%T 数据类型
21 fmt.Printf("%T\n",b)
22 fmt.Printf("%T\n",c)
23 fmt.Printf("%T\n",d) //uint8==byte
24 fmt.Printf("%T\n",e)
25 //%% 会打印一个%
26 fmt.Printf("35%%")
27}
28func main(){
29 //计算机能够识别的进制 二进制 八进制 十进制 十六进制
30 a:=123//十进制数据
31 b:=0123//八进制数据 以0开头的数据是八进制
32 c:=0xabc//十六进制 以0x开头的数据是十六进制
33 //go语言中不能直接表示二进制数据
34
35 fmt.Println(a)
36 fmt.Println(b)
37 fmt.Println(c)
38 fmt.Println("------------------------------")
39 //%b 占位符 表示输出一个二进制数据
40 fmt.Printf("二进制值为:%b\n",a)
41 fmt.Printf("二进制值为:%b\n",b)
42 fmt.Printf("二进制值为:%b\n",c)
43 fmt.Println("------------------------------")
44 //%o 占位符 表示输出一个八进制数据
45 fmt.Printf("8进制表示:%o\n",a)
46 fmt.Printf("8进制表示:%o\n",b)
47 fmt.Printf("8进制表示:%o\n",c)
48 fmt.Println("------------------------------")
49 //%x %X 占位符 表示输出一个十六进制数据 %x小写 %X 大写
50 fmt.Printf("16进制大写表示:%X\n",a)
51 fmt.Printf("16进制大写表示:%X\n",b)
52 fmt.Printf("16进制大写表示:%X\n",c)
53 fmt.Println("------------------------------")
54 s:=' '
55 fmt.Printf("%T\n",s) //int32
56 ceshi :='a'
57 fmt.Printf("%T\n",ceshi) //int32
58 fmt.Println("----------------------------")
59 zhanwei()
60}
变量类型
-
基础类型
-
布尔类型: bool
1true,false -
整形: uint8,uint16,uint32,uint64 ,int8,int16,int32,int64,int,uint,byte,rune
1uint8 8位无符号整型(0 to 255) 2uint16 16位无符号整型(0 to 65535) 3uint32 32位无符号整型(0 to 4294967295) 4uint64 64位无符号整型(0 to 2^64-1) 5int8 8位有符号整型(-128 to 127) 6int16 16位有符号整型 7int32 32位有符号整型 8int64 64位有符号整型 9平台相关的类型 uint,int (32或者是64位) 10uintptr 一个足够表示指针的无符号整数 当不同类型进行混合运算的时候,需要进行明确的显示的类型转换 11byte uint8的别名 12rune uint32的别名 -
浮点类型: float32,float64
1float32 32位浮点类型 2float64 64位浮点类型 -
复数类型: complex64,complex128
1complex64和complex128就是用来表示我们数学中的复数,复数实部和虚部,complex64的实部和虚部都是32位float,complex128的实部和虚部都是64位float
-
-
字符串类型: string
-
字符类型 byte ,rune
1 rune代表单个unicode字符 2 byte代表 utf8字符串的单个字节的值 -
错误类型:error
-
复合类型 (派生类型)
- 指针(pointer)
- 数组 (array)
- 切片 (slice)
- 结构体 (struct)
- 字典 (map)
- 接口(interface)
- 通道(chan)
- 函数 (func)
类型表示
1var value2 int32
2value1 :=64 //value1自动被推导程int类型
3value2 = value1 //编译报错
4//类型转换
5value2 = int32(value1)
数值运算
1和c语言一样 +,-,*,/,%, ++,--
比较运算符
1> ,<,>=,<=,==,!= 和c语言完全一致
位运算符
1x << y 左移 124<<2 // 结果为496
2x >> y 右移 124>>2 // 结果为31
3x ^ y 异或
4x & y 与
5x | y 或
6^x 取反 c语言 ~x表示,go语言用^x表示
浮点类型
1fvalue :=12.0 //自动推导为float64
复数
还没找到使用场景…
字符串
1var str = "hello world"
2
3 ch :=str[0] //取第一个字符
4
5fmt.Prinf("%d",len(str)) //字节数
6
7str[0]='X' //编译错误,不能重新赋值
8var str1 = "append str"
9
10str1=str + str1
字符串遍历
1func foreachstr(){
2 var str="hello world 测试"
3 for i:=0;i<len(str);i++{
4 //fmt.Println(str[i])
5 fmt.Printf("%c",str[i]) //中文乱码
6 }
7
8 var runestr =[]rune(str)
9 for _,v :=range runestr {
10 fmt.Printf("%c",v)
11 }
12}
常量
在程序运行过程中其值不能发生改变的量 称为常量
字面常量
1字面常量是指程序中硬编码的常量,如:
2 -12 //可以赋给int unint int32 int64 float32 float64 complex64 complex128
3 3.14 //浮点类型的常量
4 3.2+12i //复数类型的常量
5 true // 布尔类型的常量
6 "foo" //字符串常量
常量定义
1const PI float64 = 3.1415926
2const zero = 0.00
3const (
4 size int64 = 1024
5 eof = -1 //无类型整数常量
6)
7const u,v float32=0.3 //u=0.00, v=3.0 常量的多重赋值
8const a,b,c = 3, 4, "foo" //无类型整形 和字符串常量
内存中的位置
- 内存分为栈区,堆区 ,数据区,代码区
- 常量的存储位置在数据区,在数据区中的常量区
- 常量的存储位置在数据区 不能通过& 取地址来访问
- 常量的值不允许修改
常用无法使用取地址符,常量不同与变量在运行期分配内存,常量通常会被编译器在预处理阶段直接展开,作为数据指令使用
作用域
局部常量
全局常量
1package main
2import "fmt"
3//全局常量
4const h = 'h'
5//一次定义多个常量
6const (
7 f = "float"
8 g =3
9)
10
11func cons() {
12 //常量定义和使用
13 //在程序运行过程中其值不能发生改变的量 成为常量
14 //常量的存储位置在数据区
15 //栈区 系统为每一个应用程序分配1M空间用来存储变量 在程序运行结束系统会自动释放
16 var s1 int =10
17 var s2 int =20
18 //常量的存储位置在数据区 不能通过& 取地址来访问
19 const a int = 10
20 fmt.Println(&s1)
21 fmt.Println(&s2)
22 //a=20//常量的值不允许修改
23 fmt.Println(a)
24}
25func main(){
26 //内存分为栈区,堆区 ,数据区,代码区
27 //常量在数据区中的常量区
28 //常量一般用大写字母表示
29 fmt.Println(f,g,h) //float 3 104 //h对应的码值是104
30
31 const MAX int =10
32 b:=20
33 c:=MAX+b
34 fmt.Println(c)
35 fmt.Println(123) //字面常量
36 fmt.Println("hello world") //字面常量
37 //硬常量 32
38 d:=c+32
39 e:="hello"
40 e=e+"world"
41 fmt.Println(d)
42 fmt.Println(e)
43 cons()
44}
预定义常量
go语言预定义了这些常量: true,false和iota
iota比较特殊,可以被认为 是一个可被编译器修改的常量,在每一个const关键词出现时被重置为0,然后在下一个const出现之前,每出现一个iota,其所代表的数字会自动增1
1const (
2 c0 = iota //c0 == 0
3 c1 = iota //c2 == 1
4 c2 = iota //c2 == 2
5)
6const (
7 a = 1 << iota // a == 1 (iota在每个const开头被重置为0)
8 b = 1 << iota // b == 2
9 c = 1 << iota // c == 4
10)
11const (
12 u = iota * 42 // u == 0
13 v float64 = iota * 42 // v == 42.0
14 w = iota * 42 // w == 84
15)
16
17const 如果两个const的赋值语句时一样的,那么可以省略后i 个赋值表达式
18const (
19 c0 = iota //c0==0
20 c1 //c1==1
21 c2 //c2==2
22 _
23 c3 //c3==4
24)
25const (
26 a = 1 << iota //a = 1
27 b //b == 2
28 c //c == 4
29)
枚举
枚举中包含了一系列相关的常量,比如下面关于一个星期中每天的定义。Go 语言并不支持其他语言用于表示枚举的 enum 关键字,而是通过在 const 后跟一对圆括号定义一组常量的方式来实现枚举
1const (
2 Sunday = iota
3 Monday
4 Tuesday
5 Wednesday
6 Thursday
7 Friday
8 Saturday
9 numberOfDays
10)
和函数体外声明的变量一样,以大写字母开头的常量在包外可见(类似于 public 修饰的类属性),比如上面介绍的 Pi、Sunday 等,而以小写字母开头的常量只能在包内访问(类似于通过 protected 修饰的类属性),比如 zero、numberOfDays 等,后面在介绍包的可见性时还会详细介绍。函数体内声明的常量只能在函数体内生效
综合代码
1package main
2
3import "fmt"
4
5func iotafunc() {
6 const(
7 a=iota //0 从0开始
8 b=iota //1
9 c=iota //2
10 d=iota //3
11 )
12
13 fmt.Println(a)
14 fmt.Println(b)
15 fmt.Println(c)
16 fmt.Println(d)
17}
18
19func enums(){
20 const (
21 php = iota
22 java
23 c
24 python
25 _
26 javascript
27 )
28 const (
29 b = 1 << (10*iota)
30 kb
31 mb
32 gb
33 tb
34 pb
35 )
36 fmt.Println(php,java,c,python,javascript) // 0 1 2 3 5
37 fmt.Println(b,kb,mb,gb,tb,pb) //1 1024 1048576
38 //1073741824 1099511627776 1125899906842624
39}
40func main(){
41 //如果定义枚举是常量写在同一行值相同 换一行值加一
42 //在定义枚举时可以为其赋初始值 但是换行后不会根据值增长
43 const(
44 a=10
45 b,c=iota,iota
46 d,e
47 )
48
49 fmt.Println(a) //10
50 fmt.Println(b) //1
51 fmt.Println(c) //1
52 fmt.Println(d) //2
53 fmt.Println(e) //2
54 iotafunc()
55 enums()
56}
数据类型本质:固定内存大小的别名
数据类型的作用:编译器预算对象(变量)分配的内存空间大小
if,switch,for,goto,for range
if
注意:
-
条件语句不需要()
-
花括号必须存在 ,并且与 if , else 同行
-
在if之后,条件语句之前,可以添加变量初始化语句,使用;间隔
1package main
2import (
3 "fmt"
4 "io/ioutil"
5)
6func main(){
7 var filename = "abc.txt"
8 if content,err :=ioutil.ReadFile(filename); err != nil {
9 fmt.Println(err)
10 }else{
11 fmt.Printf("%s\n",content)
12 }
13 // fmt.Printf("%s\n",content) 报错, content作用域在if里面
14 a :="bcf1"
15 if a=="abc" {
16 fmt.Println("abc")
17 } else if a=="bcf" {
18 fmt.Println("bcf")
19 } else {
20 fmt.Println("else")
21 }
22}
switch
-
switch 会自动break, 除非使用fallthrough
-
switch 可无需表达式,case 中成立即跳出
-
fallthrough只穿透一层
如果case表达式中子表达式的结果值是无类型的常量,那么它的类型会被自动地转换为switch表达式的结果类型
1value2 := [...]int8{0, 1, 2, 3, 4, 5, 6}
2switch value2[4] { //int8
3case 0, 1: //自动转换成int8比较
4 fmt.Println("0 or 1")
5case 2, 3:
6 fmt.Println("2 or 3")
7case 4, 5, 6:
8 fmt.Println("4 or 5 or 6")
9}
1package main
2import (
3 "fmt"
4
5)
6//switch 会自动break, 除非使用fallthrough
7//switch 可无需表达式,case 中成立即跳出
8func score(score int ) string {
9 var result = ""
10 switch {
11 case score < 60 :
12 result = "F"
13 case score < 70 :
14 result = "E"
15 case score < 80 :
16 result = "C"
17 case score < 90 :
18 result = "B"
19 case score <= 100 :
20 result = "A"
21 default :
22 panic(fmt.Sprintf("错误的分数%d",score))
23 }
24 return result
25}
26//根据运算符计算
27func cal(op string,a int,b int) int{
28 var result int
29 switch op {
30 case "+" :
31 result = a+b
32 case "-" :
33 result = a-b
34 case "*" :
35 result = a*b
36 case "%" :
37 result = a%b
38 case "/" :
39 result = a/b
40 }
41 return result
42}
43// case 可以有多个值
44func manycase(a int) {
45 switch a {
46 case 1,2,3 :
47 fmt.Println(a)
48 case 4,5,6 :
49 fmt.Println(a)
50 }
51}
52// fallthrough 用法
53func fallthroughswitch(a int){
54 switch a {
55 case 1,2,3 :
56 fmt.Println("1,2,3其中一个")
57 fallthrough //只穿透一层
58 case 4,5,6 :
59 fmt.Println("4,,5,6其中一个")
60 case 7 :
61 fmt.Println("7")
62 }
63}
64func main(){
65 var a = 4
66 var b = 2
67 fmt.Println(
68 score(50),
69 score(60),
70 score(70),
71 score(80),
72 score(90),
73 score(100),
74 // score(101), //101 panic
75 )
76 fmt.Println(
77 cal("+",a,b),
78 cal("-",a,b),
79 cal("*",a,b),
80 cal("%",a,b),
81 cal("/",a,b),
82 )
83 manycase(1) //1
84 fallthroughswitch(1) //1,2,3其中一个 4,5,6其中一个
85}
type switch
1func typeswitch() {
2 var a interface{}
3 var b int = 10
4 a = b
5 switch c := a.(type) { // a.(type) 只能用来switch 内, 不然报错
6 case int:
7 fmt.Printf("x的类型市%T",c)
8 case nil:
9 fmt.Printf("x的类型市%T",c)
10 }
11}
for
一般 for 循环 为 for 单次表达式;条件表达式;末尾循环体 {中间循环体;}
go语言中 for循环没有()
go语言中只有for循环
可以只有条件表达式
也可以什么都没有表示无限循环
break 后 末尾循环体不执行
一个普通的for 循环
1func sum() int{
2 sum :=0
3 for i :=1 ;i <=100; i++ {
4 sum +=i
5 }
6 return sum
7}
无限循环
1 for {
2
3 }
4 for ;;{
5
6 }
while循环
直到i>200结束
1 var i=100
2 for {
3 if(i >200){
4 break
5 }
6 fmt.Println(i)
7 i++
8 }
do while演示
1 var i=100
2 for {
3 fmt.Println(i)
4 i++
5 if(i >200){
6 break
7 }
8 }
只要条件语句
1 var i=10
2 for i >1 && i<20 {
3 i++
4 fmt.Println(i)
5 }
综合代码
1package main
2import (
3 "fmt"
4 "strconv"
5 "os"
6 "bufio"
7)
8//一个普通的for 循环示例, 没有()
9func sum() int{
10 sum :=0
11 for i :=1 ;i <=100; i++ {
12 sum +=i
13 }
14 return sum
15}
16//可以初始化,条件,递增 ... 显示100-200 ,到200退出
17func forever(){
18 var i=100
19 for {
20 if(i > 200){
21 break
22 }
23 fmt.Println(i)
24 i++
25 }
26}
27 /*
28 2 10
29 2 5 0
30 2 2 1
31 2 1 0
32 0 1
33 */
34//可以没有初始值 ,整数转二进制
35func converttobin(a int) string{
36 result :=""
37 for ;a > 0 ; a=a/2 {
38 result = strconv.Itoa(a % 2) + result
39 }
40 return result
41}
42
43
44//一行一行读文件
45func printfile(){
46 file, err := os.Open("test.txt")
47 if err != nil {
48 panic(err)
49 }
50 scaner := bufio.NewScanner(file)
51 for scaner.Scan() {
52 fmt.Println(scaner.Text()) //一行一行读,读到结束false,跳出循环
53 }
54}
55func main(){
56 fmt.Println(sum()) //5050
57 //forever()
58 fmt.Println(converttobin(10))
59 printfile()
60}
goto
1 var j=10
2 if j<20 {
3 goto HERE
4 }
5 fmt.Println("hello") // 不执行
6 HERE:
7 fmt.Println("GOTO")
for range
-
range表达式只会在for语句开始执行时被求值一次,无论后边会有多少次迭代; -
range表达式的求值结果会被复制,也就是说,被迭代的对象是range表达式结果值的副本而不是原值。
1numbers2 := [...]int{1, 2, 3, 4, 5, 6}
2maxIndex2 := len(numbers2) - 1
3for i, e := range numbers2 { //e是副本 不会变了
4 if i == maxIndex2 {
5 numbers2[0] += e
6 } else {
7 numbers2[i+1] += e
8 }
9}
10fmt.Println(numbers2)
11
12//i=0 , numbers2[1]=3,numers[0]=1
13//i=1 numbers2[2]=3+2=5; //e 是副本 1,3,5 4,5,6
14//i=2 numerbs[3]=4+3 ;// 7 1,3,5 7,5,6
15//i=3 numers[4] =5+4 //9 1,3,5,7,9,6
16//i=4 numers[5]=6+5 //11 1,3,5,7,9,11
17//i=5 numers[0]= 7,3,5,7,9,11
for range中的坑
https://studygolang.com/articles/9701
根本原因在于for-range会使用同一块内存去接收循环中的值
数组
数组是所有语言编程中最常用的数据结构之一,Go 语言也不例外,与 PHP、JavaScript 等弱类型动态语言不同,在 Go 语言中,数组是固定长度的、同一类型的数据集合。数组中包含的每个数据项被称为数组元素,一个数组包含的元素个数被称为数组的长度。
数组声明
1 1. var 数组名 [数组大小]数据类型
2 var arr [3]int = {1,2,3}
3
4 2. 通过 := 对数组进行声明和初始化:
5 arr2 :=[3]int{1,3,5}
6 3. 省略长度
7 arr3 :=[...]int{1,2,3,4}
8
数组在初始化的时候,如果没有填满,则空位会通过对应的元素类型空值填充:
1a := [5]int{1, 2, 3}
2fmt.Println(a) //[1,2,3,0,0]
指定下标
a := [5]int{1: 3, 3: 7}
[0 3 0 7 0]
1//数组的声明方式
2func declareArr(){
3 //var 数组名 [数组大小]数据类型
4 var arr [3]int
5 arr2 :=[3]int{1,3,5}
6 arr3 :=[...]int{1,2,3,4}
7 fmt.Println(arr)
8 fmt.Println(arr2)
9 fmt.Println(arr3)
10 arr[0]=1
11 arr[1]=2
12 arr[2]=3
13// arr[3]=4 //越界,下标从0开始
14 fmt.Println(arr)
15 arr4 :=[...]string{1:"string2",0:"string1",2:"string3",4:"string5"}
16 fmt.Println(arr4) //有5个值 [string1 string2 string3 string5],下标是3的是""
17 fmt.Printf("%q\n",arr4) //["string1" "string2" "string3" "" "string5"]
18 /*
19 [0 0 0] //有默认值
20 [1 3 5]
21 [1 2 3 4]
22 [1 2 3]
23 */
24}
一维数组遍历
1/*
2 遍历数组
3*/
4func foreachArr(){
5 arr4 :=[...]string{1:"string2",0:"string1",2:"string3",4:"string5"}
6 for _,value :=range arr4 {
7 fmt.Printf("%q\n",value)
8 }
9 /*
10 "string1"
11 "string2"
12 "string3"
13 ""
14 "string5"
15 */
二维数组遍历
1/*
2 二维数组
3*/
4func foreachTwoArr(){
5 var arr [3][4]int
6 arr[0][0]=1
7 arr[0][1]=1
8 fmt.Println(arr) // [[1 1 0 0] [0 0 0 0] [0 0 0 0]]
9}
10
11 var arr [3][4]int
12 arr[0][0]=1
13 arr[0][1]=2
14 arr[0][2]=3
15 arr[0][3]=4
16 arr[1][0]=1
17 arr[1][1]=2
18 arr[1][2]=3
19 arr[1][3]=4
20 arr[2][0]=1
21 arr[2][1]=2
22 arr[2][2]=3
23 arr[2][3]=4
24 //二维数组遍历
25 for key :=range arr {
26 for key1 :=range arr[key] {
27 fmt.Println(arr[key][key1])
28 }
29 }
30 fmt.Println(arr)
31}
数组内存分布
1//数组内存分布
2 /*
3arr的地址是0xc420010180 和 第一个元素所在地址相同
4arr[0]的地址是0xc420010180
5arr[1]的地址是0xc420010188
6arr[2]的地址是0xc420010190
7数组的各个元素的地址间隔是依据数组的类型决定,比如 int64 -> 8
8int32->4...
9 */
10func innerAddress(){
11 var arr [3]int
12 arr[0]=1
13 arr[1]=2
14 arr[2]=3
15 fmt.Printf("arr的地址是%p\n",&arr)
16 fmt.Printf("arr[0]的地址是%p\n",&arr[0])
17 fmt.Printf("arr[1]的地址是%p\n",&arr[1])
18 fmt.Printf("arr[2]的地址是%p\n",&arr[2])
19}
作为函数参数
1// 参数数组 len长度要一致
2func toArg(arr [2]int){
3 fmt.Println(arr)
4}
5func main(){
6 var arr [2]int
7 toArg(arr)
8 var arr1 [3]int
9 toArg(arr1) //编译报错
10}
11
12
数组指针作为函数参数
1//数组指针,可以不带* 底层编译器会帮我们加上*
2func arrPointer(arr *[2]int){
3 arr[0]=1
4 (*arr)[1]=2
5}
6func main() {
7 var arr [2]int
8 arrPointer(&arr) //利用指针改变原来的值
9 fmt.Println(arr) //[1 2]
10}
切片
-
slice 是一个引用类型
-
slice 从底层来说,其实就是一个数据结构(struct 结构体)
1//path:Go SDK/src/runtime/slice.go 2type slice struct { 3 array unsafe.Pointer 4 len int 5 cap int 6} -
slice可以扩展,只能向后扩展,截取的时候不能超过cap 见extendingslice()
-
切片 append 操作的底层原理分析:
-
切片 append 操作的本质就是对数组扩容
-
go 底层会创建一下新的数组 newArr(安装扩容后大小) 将 slice 原来包含的元素拷贝到新的数组 newArr
-
slice 重新引用到 newArr
-
注意 newArr 是在底层来维护的,程序员不可见
-
-
slice的copy ,是相互独立的 见 copyslice()示例
-
切片作为函数是 (值传递,但是 这个值是 切片的值 是 地址)
-
切片名称 [ low : high : max ]
1 low: 起始下标位置
2 high:结束下标位置 len = high - low
3 容量:cap = max - low
4 截取数组,初始化 切片时,没有指定切片容量时, 切片容量跟随原数组(切片)。
5 s[:high:max] 从 0 开始,到 high结束。(不包含)
6 s[low:] 从low 开始,到 末尾
7 s[:high] 从 0 开始,到 high结束(不包含)。容量跟随原先容量。
切片声明
1 var s1 []int;
2 s1 = make([]int,3) //make的时候才开辟内存空间
3 s1[0]=1
4 s1[1]=2
5 s1[2]=3
- 自动推导类型创建切片 make([]数据类型,5)
1 s:=make([]int,5)
2 s[0]=123
3 s[1]=234
4 s[2]=345
5 s[3]=456
6 s[4]=567
7 //s[6]=678//err
8 //通过append 添加切片信息
9 s=append(s,678,789,8910)
10 fmt.Println(s)
3.字面量方式
1 var s4 []string=[]string{0:"maozhongyu1",1:"maozhongyu2",3:"maozhongyu3"}
2 fmt.Println(s4) //[maozhongyu1 maozhongyu2 maozhongyu3] 下标2没有是空
切片的使用
方式 1 :定义一个切片,然后让切片去引用一个已经创建好的数组
方式 2
通过 make 来创建切片.,底层也会创建数组,是由切片底层进行维护,程序员不可见
基本语法:var 切片名 []type = make([]type, len, [cap])
方式 3
定义一个切片,直接就指定具体数组,使用原理类似 make 的方式
切片遍历
1func foreachSlice(){
2 s:=make([]int,5)
3 s[0]=123
4 s[1]=234
5 s[2]=345
6 s[3]=456
7 s[4]=567
8 //遍历
9 for i := 0; i<len(s);i++ {
10 fmt.Println(s[i])
11 }
12
13 for i,v:=range s{
14 fmt.Println(i,v)
15 }
16 fmt.Println(s)
17}
切片长度,容量,扩容
1func sliceappend(){
2 //不写元素个数叫切片 必须写元素个数的叫数组,
3 var s []int=[]int{1,2,3,4,5}
4 s=append(s,6,7,8,9)
5 //容量大于等于长度
6 //fmt.Println(s)
7 fmt.Println("长度:",len(s))
8 fmt.Println("容量:",cap(s))
9 //容量每次扩展为上次的倍数
10 s=append(s,6,7,8,9)
11 //fmt.Println(s)
12 fmt.Println("长度:",len(s))
13 fmt.Println("容量:",cap(s))
14 s=append(s,6,7,8,9)
15 fmt.Println("长度:",len(s))
16 fmt.Println("容量:",cap(s))
17 //如果整体数据没有超过1024字节 每次扩展为上一次的倍数 超过1024 每次扩展上一次的1/4
18 s=append(s,6,7,8,9)
19 fmt.Println("长度:",len(s))
20 fmt.Println("容量:",cap(s))
21}
切片地址
切片名本身就是地址
1 s:=[]int{1,2,3,4,5}
2 ////切片名本身就是地址
3 ////一个字节在内存中占8bit(位)
4 fmt.Printf("%p\n",s)
5 fmt.Printf("%p\n",&s[0])
6 fmt.Printf("%p\n",&s[1])
7 fmt.Printf("%p\n",&s[2])
8 //fmt.Printf("%p\n",slice)
9 //切片名[:]获取切片中所有元素
10 slice:=s[:]
11 fmt.Println(slice)
12 news:=make([]int,5)
13 copy(news,s) //地址不同
14 fmt.Printf("%p\n",news)
15 fmt.Printf("%p\n",s)
16
切片作为函数参数(扩容后会出现结果并非预期)
切片作为函数参数是 值传递 形参可以改变实参的值
1//值传递 ,但是这个值 是指向对应 堆区空间的
2func BubbleSort(s []int) {
3 for i := 0; i < len(s)-1; i++ {
4 for j := 0; j < len(s)-1-i; j++ {
5 if s[j]>s[j+1]{
6 s[j],s[j+1]=s[j+1],s[j]
7 }
8 }
9 }
10}
11func main(){
12 s:=[]int{9,1,5,6,7,3,10,2,4,8}
13 //切片作为函数参数是地址传递 形参可以改变实参的值
14 //在实际开发者 建议使用切片代替数组
15 BubbleSort(s)
16 fmt.Println(s)
17}
综合代码
1package main
2import "fmt"
3var global_arr =[...]int{1,2,3,4,5,6,7}
4//切片的几种声明方式
5func first(){
6 arr :=[...]int{0,1,2,3,4,5,6,7}
7 s :=arr[2:6] //下标2 到 下标6 不包含6
8 fmt.Println(s) // [2 3 4 5]
9 // [:] //切全部
10 // [:2]//切下标0,1 2个元素
11 var s1 []int;
12 s1 = make([]int,3)
13 s1[0]=1
14 s1[1]=2
15 s1[2]=3
16 fmt.Println(s1) //[1 2 3]
17 s2 :=make([]string,3,6)
18 s2[0]="maozhongyu1"
19 s2[1]="maozhongyu2"
20 s2[2]="maozhongyu3"
21 fmt.Println(s2) //[maozhongyu1 maozhongyu2 maozhongyu3]
22 var s3 []string=make([]string,3)
23 s3[0]="maozhongyu1"
24 s3[1]="maozhongyu2"
25 s3[2]="maozhongyu3"
26 fmt.Println(s3) //[maozhongyu1 maozhongyu2 maozhongyu3]
27 var s4 []string=[]string{0:"maozhongyu1",1:"maozhongyu2",3:"maozhongyu3"}
28 fmt.Println(s4) //[maozhongyu1 maozhongyu2 maozhongyu3] 下标2没有是空
29}
30// 切片在内存中的布局 ,数组下标1的内存地址和切片第一个元素的 内存地址是相同的
31func second(){
32 var arr [6]int= [6]int{1,2,3,4,5,6}
33 fmt.Printf("%p\n",&arr[1]) //下标1的地址
34 slice :=arr[1:3]
35 fmt.Printf("%p\n",&slice[0])
36}
37//证明切片是对数组的引用,切片被改变了,数组相应的值也会被改变
38func update(slice []int){
39 slice[0]=100
40}
41//slice len 和cap容量
42func third(slice []int){
43 fmt.Printf("slice的长度%d\n",len(slice))
44 fmt.Printf("slice的容量%d\n",cap(slice))
45}
46//slice声明长度后不能越界,但可以动态的增加的
47func fourth(){
48 var slice []int=make([]int,6,10)
49 fmt.Println(slice) //[0 0 0 0 0 0]
50 slice[0]=100
51 slice[1]=200
52 slice[2]=200
53 slice[3]=200
54 slice[4]=200
55 slice[5]=200
56 //slice[6]=200 //越界了
57 fmt.Println("slice的长度",len(slice))
58 fmt.Println("slice的容量",cap(slice)) //10
59 fmt.Println(slice)
60}
61//切片后还可以再切片
62func reslice(){
63 fmt.Println("reslice start")
64 var slice []int=make([]int,6,10)
65 fmt.Println(slice) //[0 0 0 0 0 0]
66 slice[0]=100
67 slice[1]=200
68 slice[2]=300
69 slice[3]=400
70 slice[4]=500
71 slice[5]=600
72 fmt.Println(slice)
73 slice1 :=slice[1:]
74 fmt.Println(slice1)
75 slice1 =slice1[1:]
76 fmt.Println(slice1)
77 fmt.Println("reslice end")
78}
79//可扩展的slice
80//slice可以向后扩展,不可以向前扩展
81//向后扩展不可以超过cap(slice)
82func extendingslice(){
83 fmt.Println("extendingslice start")
84 var arr =[...]int{0,1,2,3,4,5,6,7}
85 slice1 :=arr[2:6] //2,3,4,5
86 slice2 :=slice1[3:5] //向后扩展
87 fmt.Println(arr) //[0 1 2 3 4 5 6 7]
88 fmt.Println(slice1) //[2 3 4 5]
89 fmt.Println(slice2) //[5 6]
90 fmt.Printf("slice1=%v,len(slice1)=%d,cap(slice1)=%d\n",slice1,len(slice1),cap(slice1))
91 fmt.Printf("slice2=%v,len(slice2)=%d,cap(slice2)=%d\n",slice2,len(slice2),cap(slice2))
92 fmt.Println("extendingslice end")
93}
94//append 追加
95/*
96 切片 append 操作的底层原理分析:
97 切片 append 操作的本质就是对数组扩容
98 go 底层会创建一下新的数组 newArr(安装扩容后大小) 将 slice 原来包含的元素拷贝到新的数组 newArr
99 slice 重新引用到 newArr
100 注意 newArr 是在底层来维护的,程序员不可见.
101*/
102func appendSlice(){
103 var slice1 =[]int{1,2,3,4,5,6}
104 slice2 :=append(slice1,7);
105 fmt.Println(slice2) //[1 2 3 4 5 6 7]
106 slice3 :=[]int{8,9,10}
107 slice4 :=append(slice2,slice3...)
108 fmt.Println(slice4) //[1 2 3 4 5 6 7 8 9 10]
109}
110//删除下标为3的元素
111func deleteslice(){
112 fmt.Println("删除slice下标为3的元素")
113 var slice1 =[]int{1,2,3,4,5,6}
114 slice2 :=slice1[:3]
115 slice3 :=slice1[4:]
116 slice1 =append(slice2, slice3...)
117 fmt.Println(slice1) // [1 2 3 5 6]
118}
119//slice 的copy
120func copySlice(){
121 fmt.Println("slice的copy")
122 var slice =make([]int,8,16)
123 slice1 :=[]int{1,2,3,4,5}
124 copy(slice,slice1)
125 fmt.Println(slice) //[1 2 3 4 5 0 0 0]
126 slice1[0]=100
127 fmt.Println(slice) //[1 2 3 4 5 0 0 0] slice1和slice 是独立的,不影响
128}
129func main(){
130 first()
131 second()
132 slice :=global_arr[1:]
133 fmt.Println("before update")
134 fmt.Printf("slice=%v\n",slice)
135 fmt.Printf("global_arr=%v\n",global_arr)
136 update(slice)
137 fmt.Println("after update")
138 fmt.Printf("slice=%v\n",slice)
139 fmt.Printf("global_arr=%v\n",global_arr)
140 third(slice)
141 fourth()
142 reslice()
143 extendingslice()
144 appendSlice()
145 deleteslice()
146 copySlice()
147}
打散符号 …
1S1 = append(s1,s2...)
map
var map 变量名 map[keytype]valuetype
key 可以是什么类型
- golang 中的 map,的 key 可以是很多种类型,比如 bool, 数字,string, 指针, channel , 还可以是只 包含前面几个类型的 接口, 结构体, 数组
- 通常 key 为 int 、string
- 注意: slice, map 还有 function 不可以,因为这几个没法用 == 来判断
map的长度是自动扩容的
map中的数据是无序存储的
map名本身就是一个地址
访问不存在的下标,获得对应的零值
声明方式
1//1.
2 var a map[string]string
3 a = make(map[string]string,10)
4 fmt.Println(a)
5 a["key1"]="value1"
6 a["key2"]="value2"
7 fmt.Println(a) //map[key1:value1 key2:value2]
8
9//2.
10 b :=make(map[string]int)
11 b["key1"]=10
12 b["key2"]=11
13 fmt.Println(b) //map[key1:10 key2:11]
14 //直接声明元素
15
16//3.
17 var c = map[string]string{"key1":"values1","key2":"value2"} //map[key1:values1 key2:value2]
18 fmt.Println(c)
map删除
1 b :=make(map[string]int)
2 b["key1"]=10
3 b["key2"]=11
4 delete(b,"key1")
5 fmt.Println(b) //map[key2:11]
map是否有这个下标
1 b :=make(map[string]int)
2 b["key1"]=10
3 b["key2"]=11
4 a :=b["key1"]
5 fmt.Println(a) //10
6 if c,ok:=b["key3"];ok{
7 fmt.Println(c)
8 }else{
9 fmt.Println("key3 not exists")
10 }
map遍历
1 b :=make(map[string]int)
2 b["key1"]=10
3 b["key2"]=11
4 for key,value :=range b {
5 fmt.Println(key,value)
6 }
7 for key := range b {
8 fmt.Println(key) //打印的是下标
9 }
map作为函数参数
map作为函数参数是。 值传递 (map 本身是地址)
1package main
2
3import "fmt"
4
5func demo(m map[int]string){
6 //map在函数中添加数据 可以的 影响主调函数中实参的在
7 m[102]="杨二郎"
8 m[103]="唐老二"
9 fmt.Println(len(m))
10 delete(m,101)
11 fmt.Println(len(m))
12}
13func main() {
14 m:=make(map[int]string,1)
15 m[101]="孙悟空"
16 fmt.Println(len(m))
17 //fmt.Println(cap(m))//err
18 //map作为函数参数是地址传递 (引用传递)
19 demo(m)
20 fmt.Println(m)
21}
map的value赋值问题
- 值引用的特点是只读
1package main
2
3import "fmt"
4
5type Student struct {
6 Name string
7}
8
9//key string, value Student struct
10//var list map[string]Student
11var list map[string]*Student
12
13/*
14func main() {
15
16 list = make(map[string]Student)
17
18 //定义了一个结构体
19 student := Student{"Aceld"}
20
21 //map添加了一条数据, key student, value Student{"Aceld"}
22 list["student"] = student //值拷贝 过程, map中的value是新创建的一个结构体, 该结构体的属性是只读的
23 list["student"].Name = "LDB" //报错 list["student"]是值引用,值引用的特点是只读
24
25 fmt.Println(list["student"])
26}
27*/
28
29/*
30 方法一:
31func main() {
32
33 list = make(map[string]Student)
34
35 //定义了一个结构体
36 student := Student{"Aceld"}
37
38 //map添加了一条数据, key student, value Student{"Aceld"}
39 list["student"] = student //值拷贝, map中的value是新创建的一个结构体, 该结构体的属性是只读的
40
41 //创建一个临时的student结构体
42 tmpStudent := list["student"]
43 tmpStudent.Name = "LDB"
44 list["student"] = tmpStudent
45 //中间发生两次值拷贝,性能比较差
46
47 fmt.Println(list["student"])
48}
49*/
50
51/*方法二*/
52func main() {
53
54 list = make(map[string]*Student)
55
56 //定义了一个结构体
57 student := Student{"Aceld"}
58
59 //map添加了一条数据, key student, value Student{"Aceld"}
60 list["student"] = &student
61
62 //每次修改的是指针指向的studeng 空间,指针本身是常指针,不能修改,只读,但是指向student 是可以随便修改的,
63 //而且这里不是指拷贝,而是指针的赋值
64 list["student"].Name = "LDB"
65
66 fmt.Println(list["student"])
67}
指针
从传统意义上说,指针是一个指向某个确切的内存地址的值。这个内存地址可以是任何数据或代码的起始地址,比如,某个变量、某个字段或某个函数。
在 Go 语言中还有其他几样东西可以代表“指针”。其中最贴近传统意义的当属uintptr类型了。该类型实际上是一个数值类型,也是 Go 语言内建的数据类型之一。
所有指针在32位系统下占4字节
所有指针在64位系统下占8字节
指针就是地址。 指针变量就是存储地址的变量。
*p : 解引用、间接引用。
指针可以操作其指向存储区的值
指针必须初始化,访问野指针和空指针对应的内存空间都会报错
声明了一个指针 默认值为nil(空指针值为0)指向了内存地址编号为0的空间
1 var p *int //空指针
2 //p=0xc042058080//野指针 指针变量指向了一个未知的空间
3 //访问野指针和空指针对应的内存空间都会报错
4 //*p=123 //err 在上面加一行 p=new(int) 即可
5 fmt.Println(p) //nil
6 p = new(int)
7 fmt.Println(*p) //0
1package main
2import "fmt"
3
4/*
5结果:
6p的地址是0xc42000c028
7p本身是0xc420012068
8p的指向的值是2
9a现在的值是3
10*/
11func first(){
12 var a = 2
13 var p *int=&a
14 fmt.Printf("p的地址是%p\n",&p)
15 fmt.Printf("p本身是%v\n",p)
16 fmt.Printf("p的指向的值是%v\n",*p)
17 //*p 解引用,间接引用
18 *p = 3
19 fmt.Printf("a现在的值是%v\n",a)
20}
21//利用指针交换值
22func swap (a,b *int){
23 *a,*b=*b,*a
24}
25func main() {
26 first()
27 //go的指针不能运算
28 a,b :=3,4
29 swap(&a,&b)
30 fmt.Println(a,b) //4,3
31}
new操作
new 函数会在heap上申请一片内存空间
1package main
2import "fmt"
3func main() {
4 var p *int//nil
5 fmt.Println(p) //nil
6 //为指针变量创建一块内存空间
7 //在堆区创建空间
8 p=new(int)//new 创建好的空间值为数据类型的默认值
9 //打印p的值
10 fmt.Println(p) //0xc000098008
11 //打印p指向空间的值
12 fmt.Println(*p) //0
13}
数组指针
直接使用指针[下标]操作数组元素,go语言内部维护
指针的值 == &arr == &arr[0]
可以使用 len(指针变量) 求数组元素个数
1package main
2
3import "fmt"
4
5func test1() {
6 var arr [5]int = [5]int{123,2,3,4,5}
7 fmt.Printf("%p\n",&arr) //0xc000088000
8 fmt.Printf("%p\n",&arr[0]) //0xc000088000
9 //p:=&arr
10 //定义指针指向数组
11 var p *[5]int
12 //将指针变量和数组建立关系
13 p=&arr //5要和数组对硬上
14 fmt.Println(*p) //[123 2 3 4 5]
15 fmt.Println(arr) //[123 2 3 4 5]
16 fmt.Println((*p)[0]) //123
17 //直接使用指针[下标]操作数组元素
18 fmt.Println(p[0]) //go语言内部维护 123
19 fmt.Printf("%p\n",p) //0xc000088000
20 fmt.Printf("%T\n",p)//*[5]int
21 //可以通过指针间接操作数组
22 (*p)[0]=199
23 fmt.Println(arr) //[199 2 3 4 5]
24
25
26}
27func main(){
28 test1()
29 var arr [5]int = [5]int{123,2,3,4,5}
30 //指向数组的指针
31 p:=&arr //*[5]int
32 p1:=&arr[0]//*int
33 fmt.Printf("%T\n",p) //*[5]int
34 fmt.Printf("%T\n",p1) //*int
35 //len(指针变量)元素个数
36 fmt.Println(len(p)) //5
37 for i := 0; i<len(p);i++ {
38 fmt.Println(p[i])
39 }
40 fmt.Printf("%p\n",p) //0xc00008e000
41 fmt.Printf("%p\n",&arr) //0xc00008e000
42 fmt.Printf("%p\n",&arr[0]) //0xc00008e000
43}
切片指针
切片本身就是一个地址
切片的指针其实就是一个二级指针
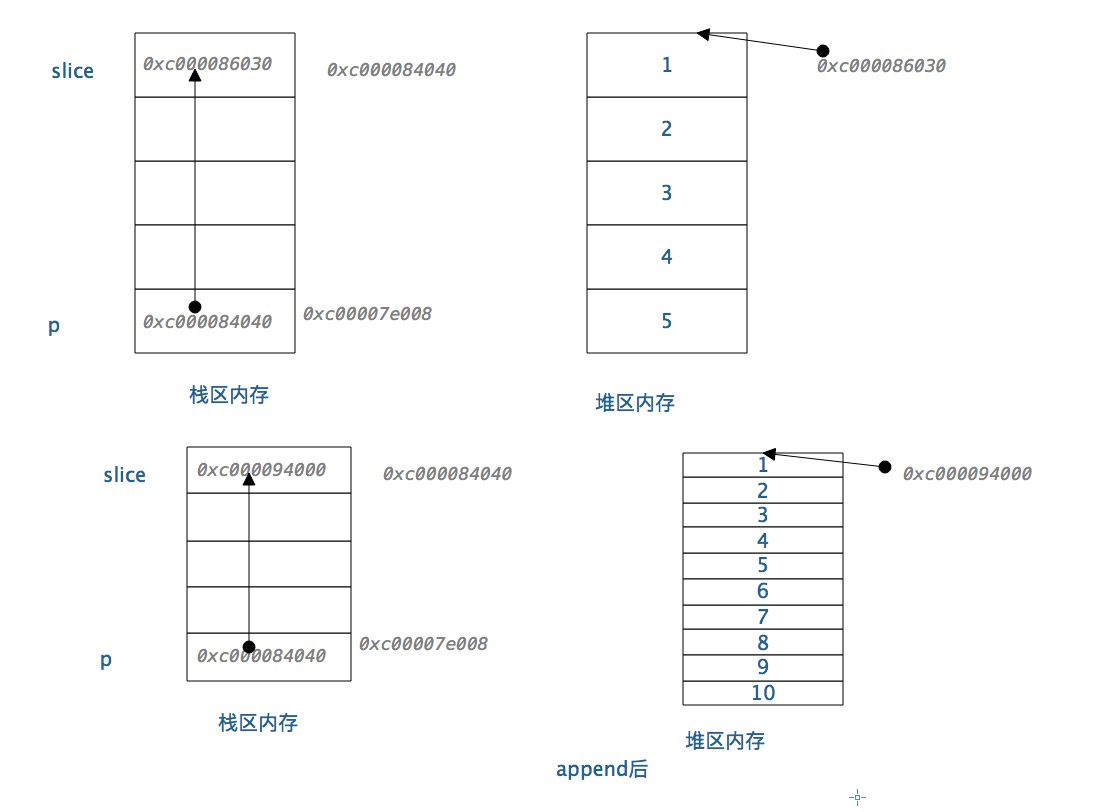
切片的地址,append 后是不会改变的。 切片的值是可能改变的。 切片的值就是 指向堆区的,堆区里面的内容会改变。
切片指针和append后的示例图
1package main
2
3import "fmt"
4
5func main() {
6 var slice []int = []int{1, 2, 3, 4, 5}
7 //p:=&slice //*[]int
8 var p *[]int //二级指针
9 p = &slice
10 fmt.Printf("%T\n", p) //*[]int
11 //切片名本身就是一个地址
12 fmt.Printf("%p\n", slice) // 0xc000070030
13 fmt.Printf("%p\n", p) // 0xc00006c020
14 fmt.Printf("%p\n", &slice) //0xc00006c020
15 fmt.Printf("%p\n", *p) // 0xc000070030
16 (*p)[1] = 200 //ok
17 //p[1]=123 //err 不能通过指针访问切片中的元素
18 fmt.Println(slice)
19 fmt.Println(*p)
20
21 test01()
22}
23
24
25func test01() {
26 var slice []int = []int{1, 2, 3, 4, 5}
27 fmt.Printf("%p\n", slice) //0xc000086030
28 //p:=&slice//*[]int
29 var p *[]int //二级指针
30 p = &slice
31 fmt.Printf("%p\n", p) //0xc000084040
32 fmt.Printf("%p\n", &slice) //0xc000084040
33 fmt.Printf("%p\n", &p) //0xc00007e008
34 //左边 *p就是slice,
35 //在使用append添加数据是 切片的地址可能或发生变量 如果容量扩充导致输出存储溢出 切片会自动找寻新的空间存储数据
36 *p = append(*p, 6, 7, 8, 9, 10)
37 fmt.Printf("%p\n", slice) // 0xc000094000
38 fmt.Printf("%p\n", &slice) // 0xc000084040
39 fmt.Printf("%p\n", p) //0xc000084040
40 fmt.Printf("%p\n", &p) //0xc00007e008
41 fmt.Println(slice)
42}
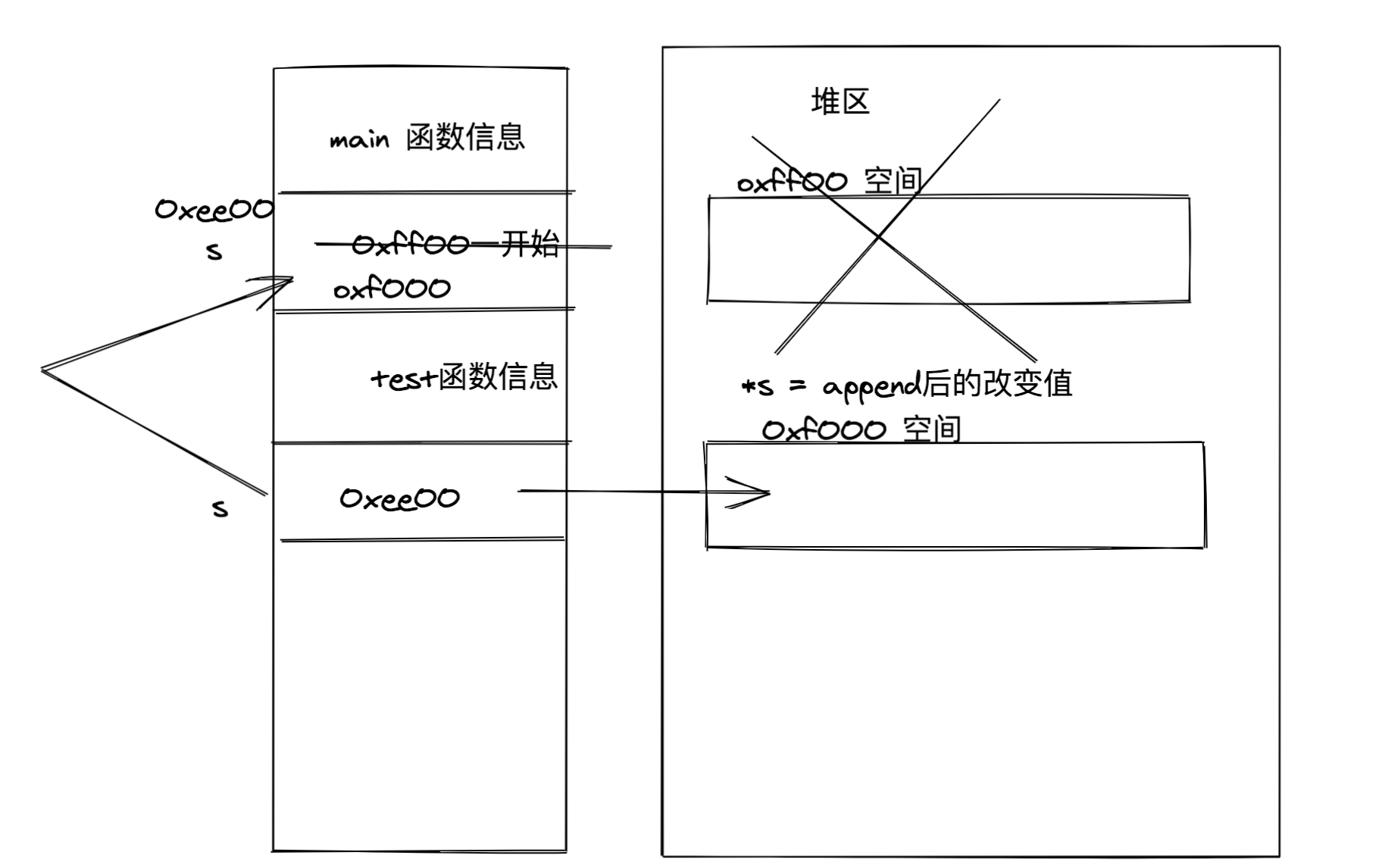
切片作为函数参数
输出[1,2,3]
1func test(s []int) []int {
2 s = append(s,4,,5,6)
3 return s
4}
5func main() {
6 s :=[]int{1,2,3}
7 test(s)
8 fmt.println(s)
9}
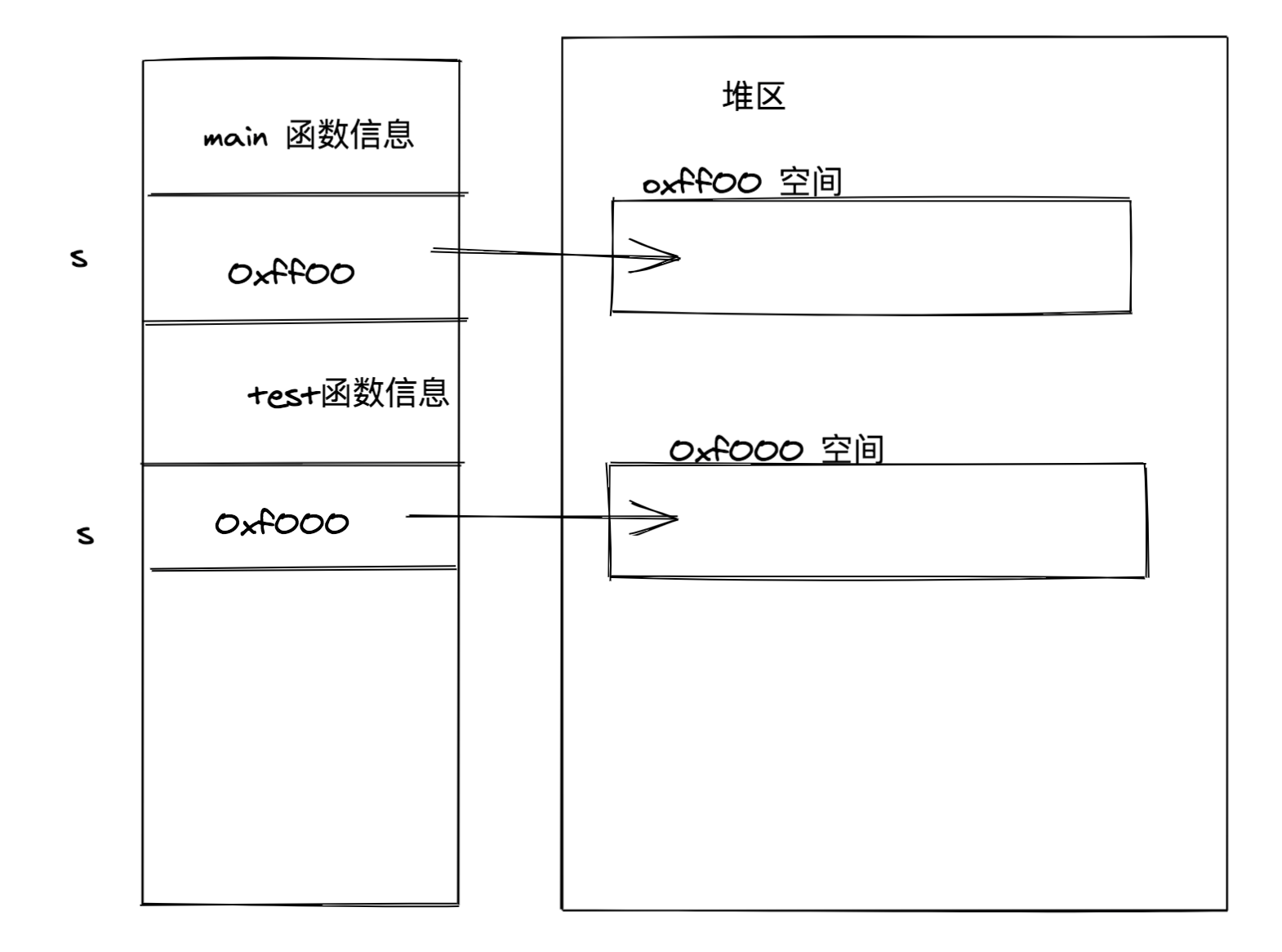
切片指针作为函数参数
输出[1,2,3,4,5,6]
1func test(s *[]int) {
2 *s = append(*s ,4,5,6)
3}
4func main() {
5 s :=[]int {1,2,3}
6 test(&s)
7 fmt.Println(s)
8}
new 创建切片指针
1package main
2import "fmt"
3func main() {
4 var p *[]int
5 fmt.Printf("%p\n",p) //ox0
6 p=new([]int)
7 fmt.Printf("%p\n",p) //0xc0000b4000
8 *p=append(*p,1,2,3)
9 //for i := 0; i<len(*p);i++ {
10 // fmt.Println((*p)[i])
11 //}
12 for i,v:=range *p{
13 fmt.Println(i,v)
14 }
15 //fmt.Println(len(*p))
16}
指针数组
1package main
2
3import "fmt"
4
5func main() {
6
7 //var arr [3]int ->int
8 //指针数组
9 var arr [3]*int //->*int
10 a:=10
11 b:=20
12 c:=30
13
14 arr[0]=&a
15 arr[1]=&b
16 arr[2]=&c
17 fmt.Println(arr)
18 fmt.Printf("%p\n",&a)
19 fmt.Printf("%p\n",&b)
20 fmt.Printf("%p\n",&c)
21 //通过指针数组改变变量的值
22 *arr[1]=2 // arr[1] 优先级高
23 fmt.Println(b)
24 //变量指针数组对应的内存空间的值
25 for i := 0; i < len(arr); i++ {
26 fmt.Println(*arr[i])
27 }
28
29}
指针切片
1package main
2
3import "fmt"
4
5func main() {
6 //指针切片
7 var slice []*int
8 a:=10
9 b:=20
10 c:=30
11 d:=40
12 slice=append(slice,&a,&b,&c)
13 slice=append(slice,&d)
14 fmt.Println(slice)
15 for i,v:=range slice{
16 fmt.Printf("%T\n",v)
17 fmt.Println(i,*v)
18 }
19}
结构体指针
1package main
2
3import "fmt"
4
5type Student struct {
6 name string
7 id int
8 age int
9 sex string
10}
11func test01() {
12 //定义结构体变量
13 //var 结构体名 结构体数据类型
14 var stu Student=Student{id:101,name:"多啦A梦",age:100,sex:"男"}
15 //结构体变量.成员=值
16
17 //定义结构体指针指向变量的地址
18 var p *Student
19 ////结构体指针指向结构体变量地址
20 p=&stu
21 p1:=&stu
22 p2:=&stu.name
23 fmt.Printf("%T\n",p1)//*main.Student
24 fmt.Printf("%T\n",p2)//*string
25 fmt.Printf("%T\n",p) //*main.Student
26 fmt.Printf("%p\n",&stu) //0xc00009a090
27 fmt.Printf("%p\n",&stu.id) //0xc00009a0a0
28 ////结构体成员地址
29 fmt.Printf("%p\n",&stu.name) //0xc00009a090 第一个元素地址和 结构体地址相同
30 fmt.Printf("%p\n",&stu.id)
31 fmt.Printf("%p\n",&stu.age)
32 fmt.Printf("%p\n",&stu.sex)
33}
34
35func test02(){
36 var stu Student=Student{id:101,name:"多啦A梦",age:100,sex:"男"}
37 var p *Student
38 p=&stu
39 //通过结构体指针间接操作结构体成员
40 //(*p).name="大熊"
41 //通过指针可以直接操作结构体成员
42 p.name="静香"
43 p.age=18
44 p.sex="女"
45 fmt.Println(stu)
46}
47
48func main(){
49 //结构体切片
50 var stu []Student=make([]Student,3)
51 p:=&stu//*[]Student //结构体切片指针
52 //stu[0]=Student{"小猪佩奇",1,10,"女"}
53 (*p)[0]=Student{"小猪佩奇",1,10,"女"}
54 (*p)[1]=Student{"野猪佩奇",2,15,"女"}
55 (*p)[2]=Student{"猪刚鬣",3,1000,"男"}
56 //append在切片长度后添加数据
57 *p=append(*p,Student{"小猪佩奇",1,10,"女"})
58 //fmt.Printf("%T\n",p)
59 //fmt.Println(stu)
60 for i := 0; i<len(*p);i++ {
61 fmt.Println((*p)[i])
62 }
63}
多级指针
1package main
2
3import "fmt"
4
5var pp **int
6func main() {
7 a:=10
8 p:=&a
9 pp:=&p//二级指针 二级指针存储一级指针的地址
10 p3:=&pp//三级指针 存储二级指针的地址
11 fmt.Println(pp) //0xc000078010
12 fmt.Println(*p3)//0xc000078010
13 //变量a 的值
14 fmt.Println(**pp)
15 fmt.Println(*p)
16 fmt.Println(a)
17 fmt.Printf("%T\n",a) //int
18 fmt.Printf("%T\n",p) //*int
19 fmt.Printf("%T\n",pp) //**int
20 fmt.Printf("%T\n",p3) //***int
21}
内存四区
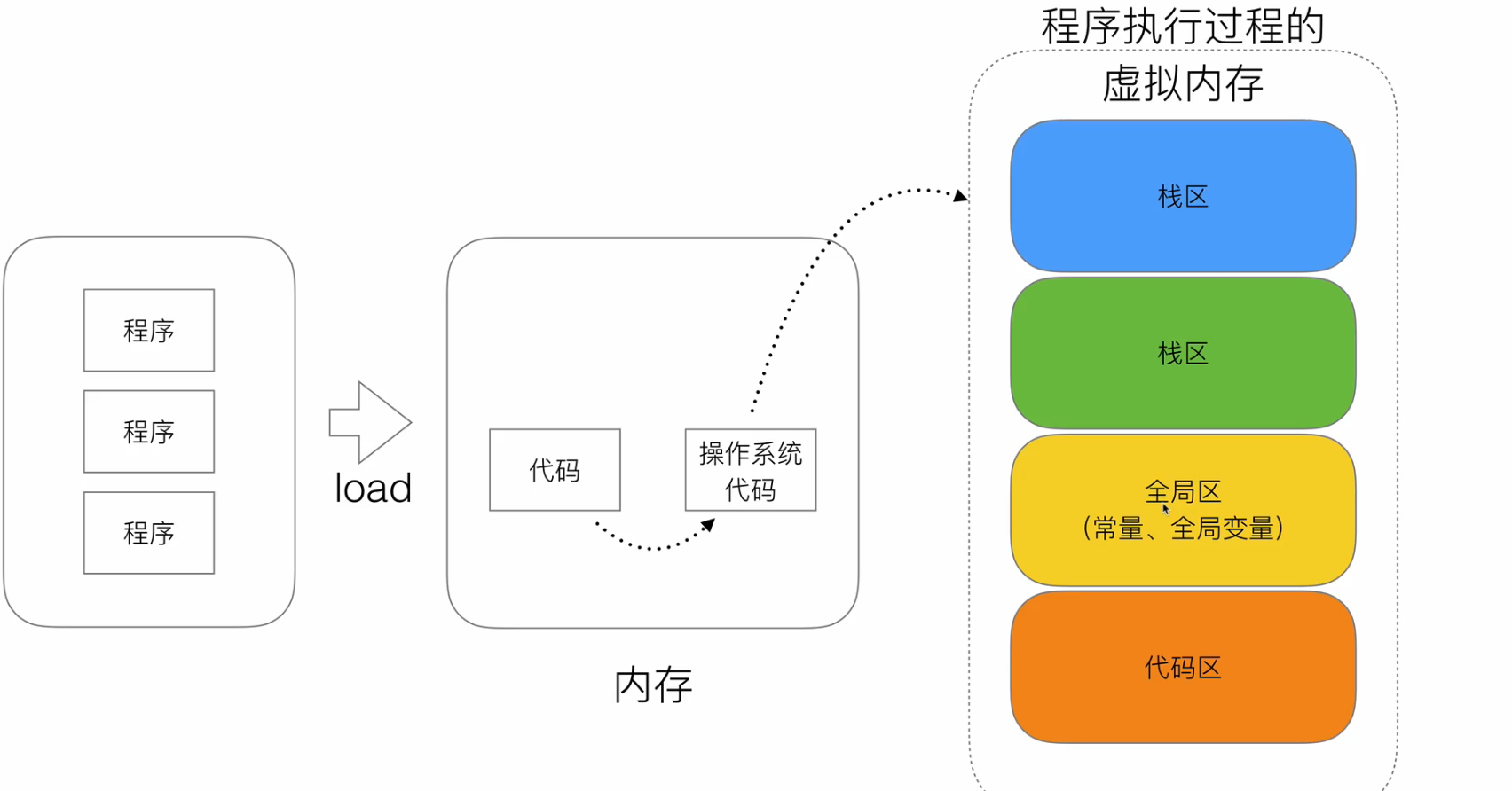
流程说明:
- 操作系统把物理硬盘代码load 到内存
- 操作系统把代码分成4个区
- 操作系统找到main入口执行
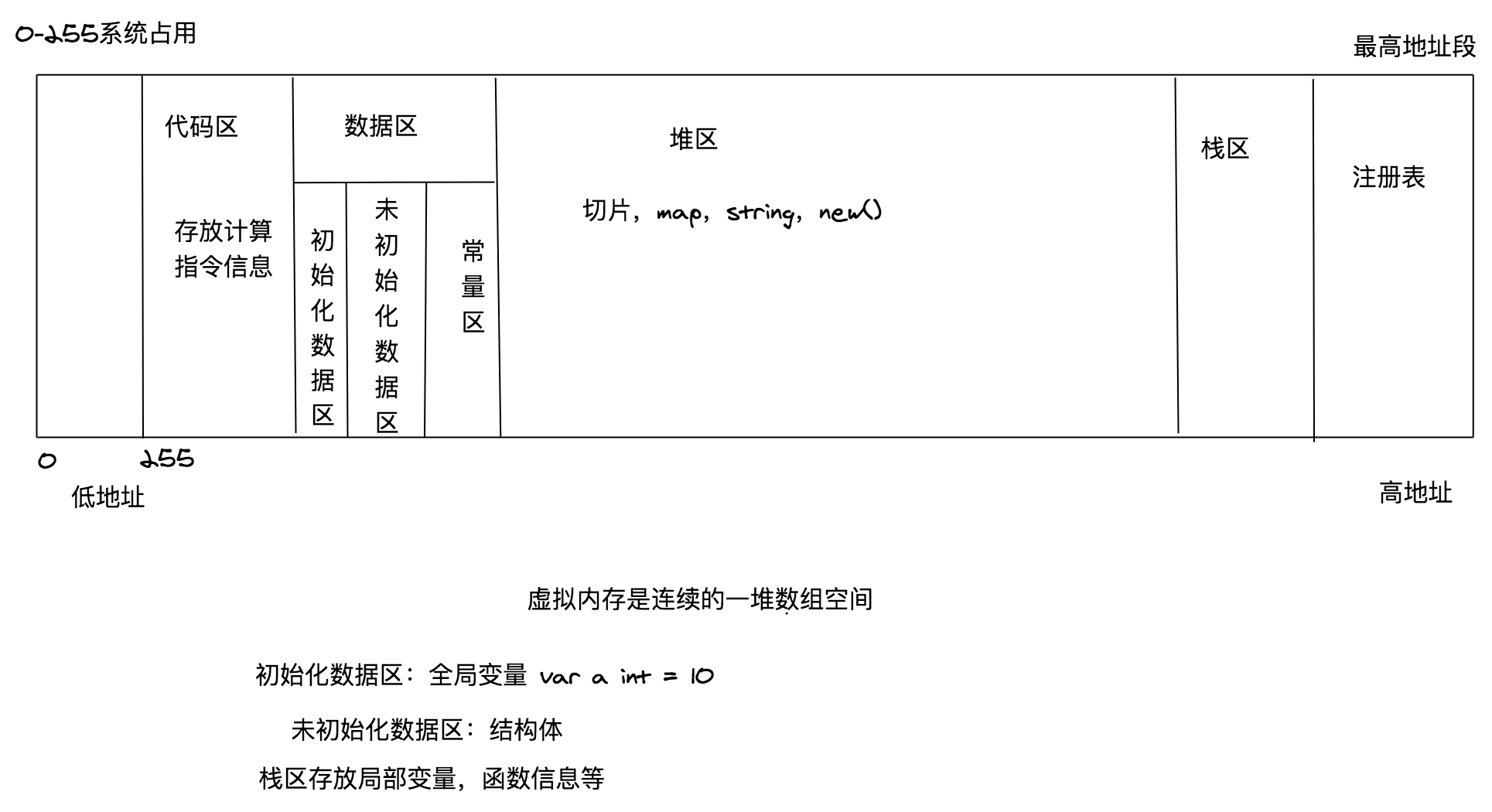
栈区:空间较小、要求数据读写性能高、数据存放时间短暂。由编译器自动分配和释放,存放函数的参数、函数的调用流程方法地址、
局部变量等(局部变量如果产生了逃逸现象,可能会挂在堆区
堆区
空间充裕、数据存放时间较长。一般由开发者分配和释放(但是golang中会根据变量等逃逸现象来选择是否分配到栈上还是堆上)
启动golang的gc由gc清除机制自动回收
全局区-静态全局变量区
全局变量的开辟是在程序在main之前就已经放在内存中。
尽量减少全局变量的设计
全部区-常量区
常量为 存放数值字面值 单位(在内存中符号表中存在,不在栈上,也不在堆上)。既不可修改。不可取地址,因为字面量符号 无地址可言
函数中切片名是在栈区,数据是在堆区
内存的基本单位是字节
堆区由垃圾回收机制控制
string 字符串是 底层是字节切片
栈帧内存布局
32位操作内存图为例, 3g-》4g 内核空间,其他是用户空间。
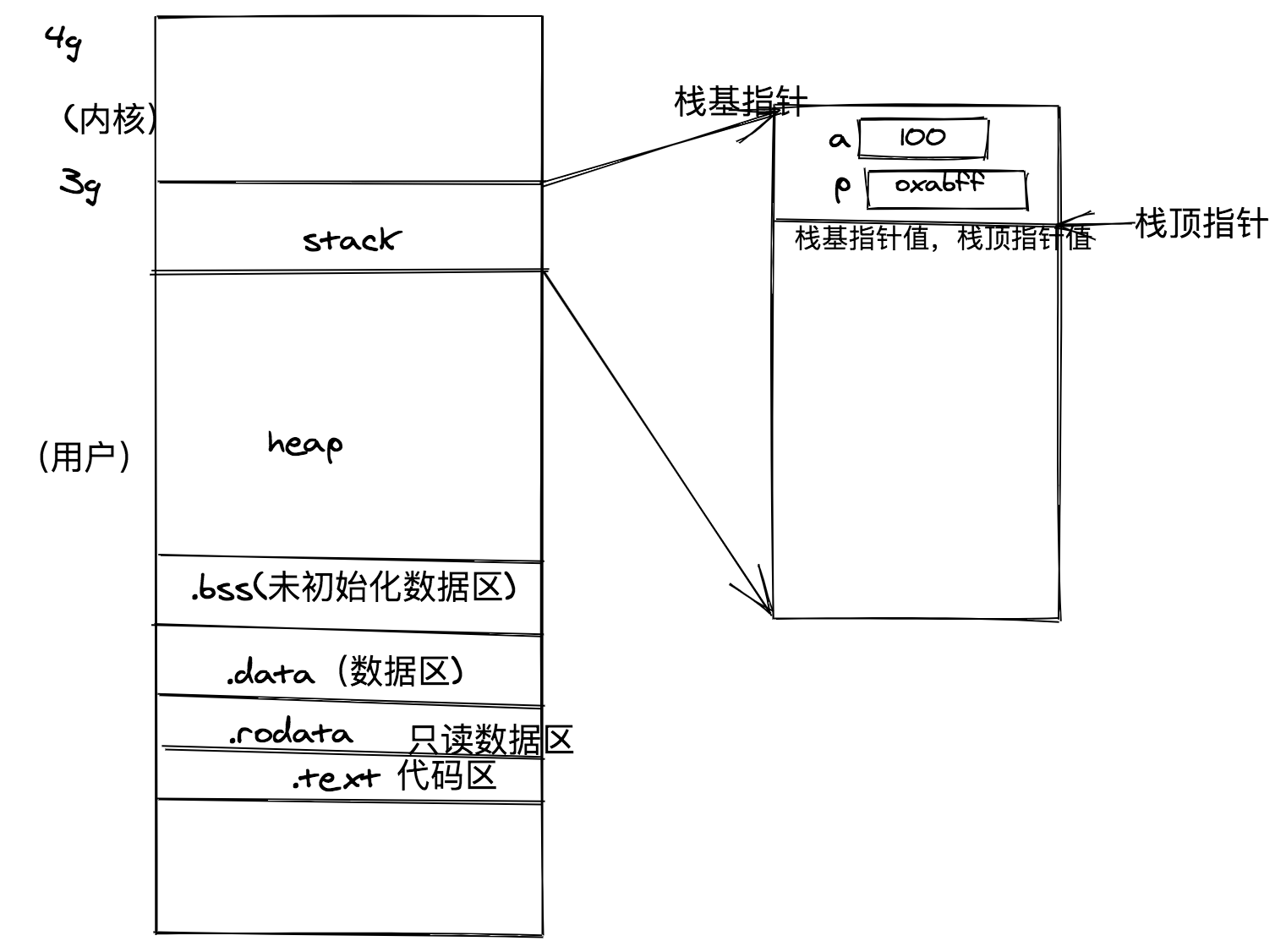
上图最右侧的请忽略
1func test(m int) {
2 var b int = 1000
3 b += m
4}
5
6func main(){
7 var a int =100
8 var p *int
9 p=new(int) //在堆区开辟内存空间
10 *p=1000
11
12 test(10)
13}
| 空间 | 存放内容 |
|---|---|
| stack(栈) | 函数和函数内定义的引用(变量名) |
| heap(堆) | 引用所对应的实体 |
| .bss(未初始化数据区) | 未初始化(赋初值)的全局变量 |
| .data(数据区) | 已初始化的全局变量 |
| . rodata(只读数据区) | 常量 |
| .text(代码区) |
栈在初始的时候存在两个指针,一个是栈基指针,一个是栈顶指针,他们刚开始都指向栈的基地址,当创建一个函数,栈顶指针会往下挪一段距离,此时两个指针指向地址中间的这段空间就是函数的栈帧,例如代码中的main()函数就有一块自己的栈帧,其中保存的是局部变量(a、p)、形参和内存地址描述值。
内存地址描述值:考虑在main()函数中我们又创建了一个test()函数,此时栈基指针会往下挪指向原先栈顶指针的位置,栈顶指针则往下挪若干距离,这段新产生的空间就是test()的栈帧,由于两个指针的移动,main栈帧的位置就无法被描述了,所以需要main栈帧自己记录原先的栈基地址和栈顶地址,称为内存地址描述值。
另外,局部变量和形参的地位是等同的,如test()中的b和m。
当函数执行完毕,栈帧空间会被释放。
栈空间非常小,只有1MB~8MB,所以以上创建栈帧回收栈帧操作都由操作系统完成
堆空间相对比较大,有至少1GB的空间,且go语言中也有垃圾回收机制,帮助回收不用的内存,但对于不再使用的空间,应将指针置为nil,以便提示系统回收。
栈帧: 用来给函数运行提供内存空间。 取内存于 stack(栈) 上。
当函数调用时,产生栈帧。函数调用结束,释放栈帧。
栈帧存储: 1. 局部变量。 2. 形参。 (形参与局部变量存储地位等同) 3. 内存字段描述值
stack 默认是1mb ,可以扩展,但是还是很小
指针的作为函数参数
指针的函数传参(传引用)。
传地址(引用):将形参的地址值作为函数参数传递。
传值(数据值):将实参的值 拷贝一份给形参。
传引用:在A栈帧内部,修改B栈帧中的变量值。
内存的释放
堆区内存,用完后,可以让它等于nil ,gc会回收。
new和make
2者都是内存的分配(堆上),但是make 只用于slice,map以及channel 的初始化(非零值);
而new 用于类型的内存分配,并且内存置为零。 make 返回的是这3个引用类型的本身,而new 返回的是指向类型的指针
new: 一般是用来初始化值类型指针的,new([]int) 也可以哦。
make:是用来初始化slice, map,chan