String类型内存开销大
图片ID和图片存储对象ID都是10位数,我们可以用两个8字节的Long类型表示这两个ID。因为8字节的Long类型最大可以表示2的64次方的数值,所以肯定可以表示10位数。但是,为什么String类型却用了64字节呢?
其实,除了记录实际数据,String类型还需要额外的内存空间记录数据长度、空间使用等信息,这些信息也叫作元数据。当实际保存的数据较小时,元数据的空间开销就显得比较大了,有点“喧宾夺主”的意思。
String类型就会用简单动态字符串(Simple Dynamic String,SDS)
- buf:字节数组,保存实际数据。为了表示字节数组的结束,Redis会自动在数组最后加一个“\0”,这就会额外占用1个字节的开销。
- len:占4个字节,表示buf的已用长度。
- alloc:也占个4字节,表示buf的实际分配长度,一般大于len。
在SDS中,buf保存实际数据,而len和alloc本身其实是SDS结构体的额外开销
对于String类型来说,除了SDS的额外开销,还有一个来自于RedisObject结构体的开销。
Redis的数据类型有很多,而且,不同数据类型都有些相同的元数据要记录(比如最后一次访问的时间、被引用的次数等),所以,Redis会用一个RedisObject结构体来统一记录这些元数据,同时指向实际数据。
一个RedisObject包含了8字节的元数据和一个8字节指针,这个指针再进一步指向具体数据类型的实际数据所在,例如指向String类型的SDS结构所在的内存地址
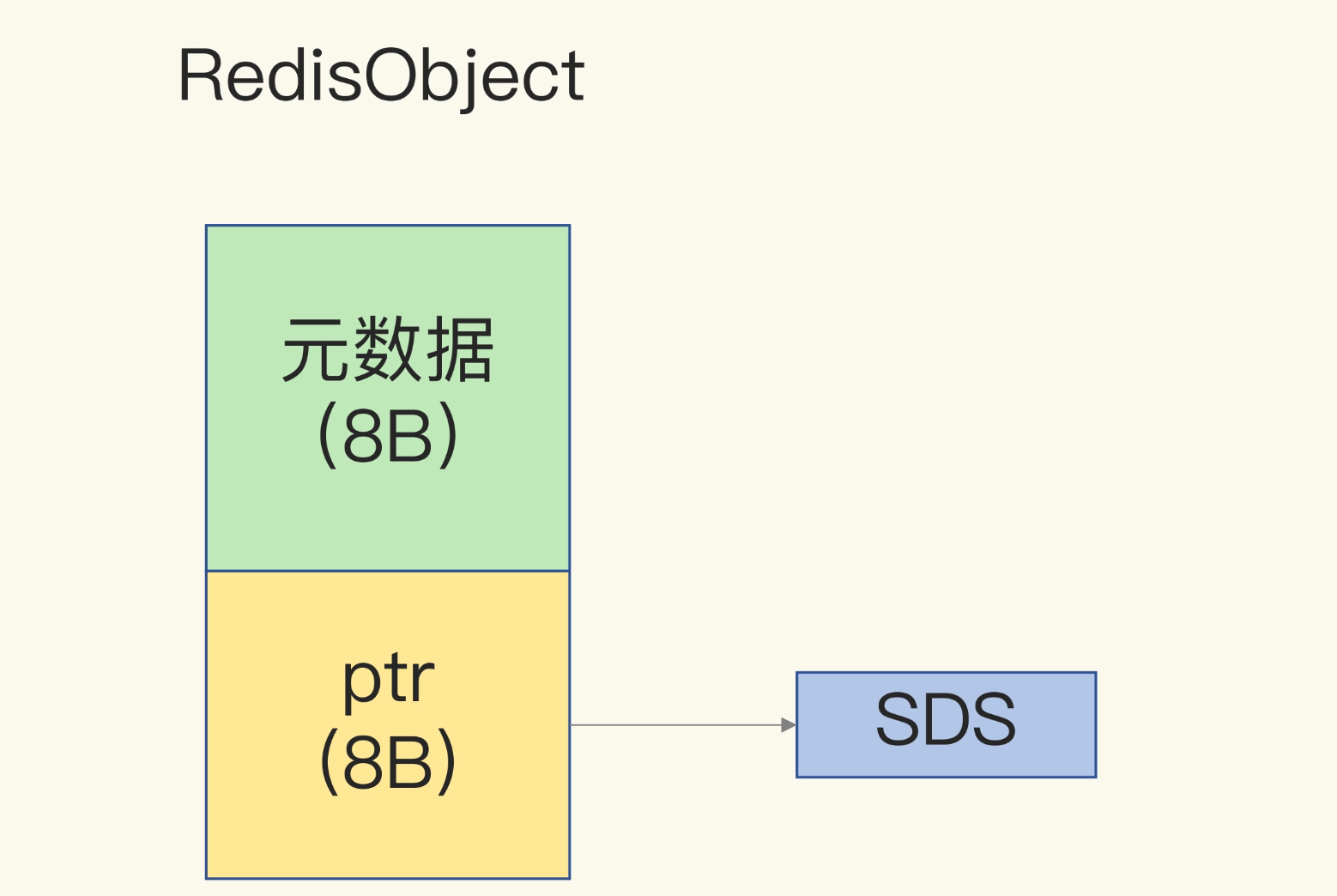
为了节省内存空间,Redis还对Long类型整数和SDS的内存布局做了专门的设计。
一方面,当保存的是Long类型整数时,RedisObject中的指针就直接赋值为整数数据了,这样就不用额外的指针再指向整数了,节省了指针的空间开销。
另一方面,当保存的是字符串数据,并且字符串小于等于44字节时,RedisObject中的元数据、指针和SDS是一块连续的内存区域,这样就可以避免内存碎片。这种布局方式也被称为embstr编码方式。
当然,当字符串大于44字节时,SDS的数据量就开始变多了,Redis就不再把SDS和RedisObject布局在一起了,而是会给SDS分配独立的空间,并用指针指向SDS结构。这种布局方式被称为raw编码模式。
为了帮助你理解int、embstr和raw这三种编码模式,我画了一张示意图,如下所示:
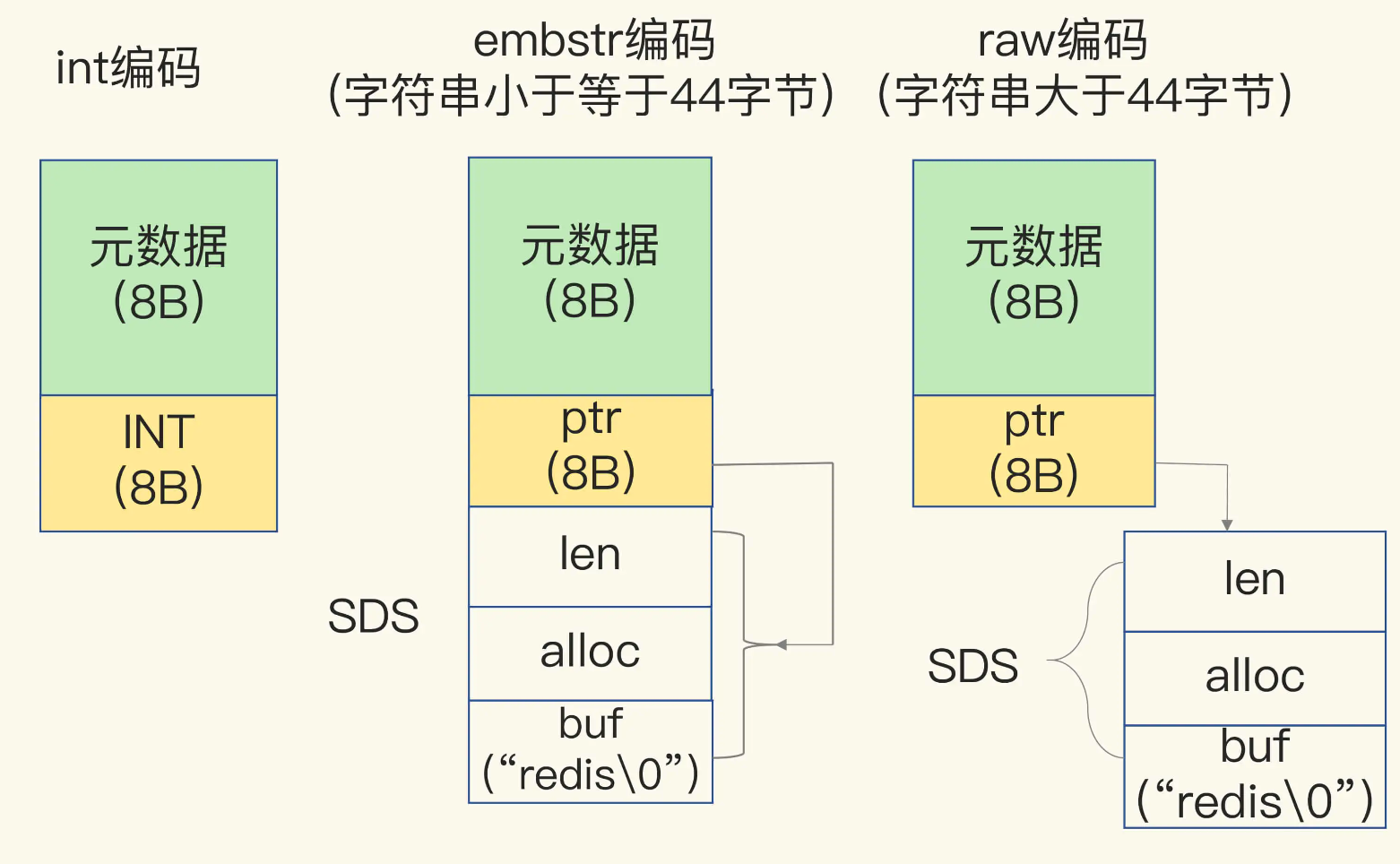
因为10位数的图片ID和图片存储对象ID是Long类型整数,所以可以直接用int编码的RedisObject保存。每个int编码的RedisObject元数据部分占8字节,指针部分被直接赋值为8字节的整数了。此时,每个ID会使用16字节,加起来一共是32字节。但是,另外的32字节去哪儿了呢?
key也是一个redisObject
Redis会使用一个全局哈希表保存所有键值对,哈希表的每一项是一个dictEntry的结构体,用来指向一个键值对。dictEntry结构中有三个8字节的指针,分别指向key、value以及下一个dictEntry,三个指针共24字节,如下图所示:
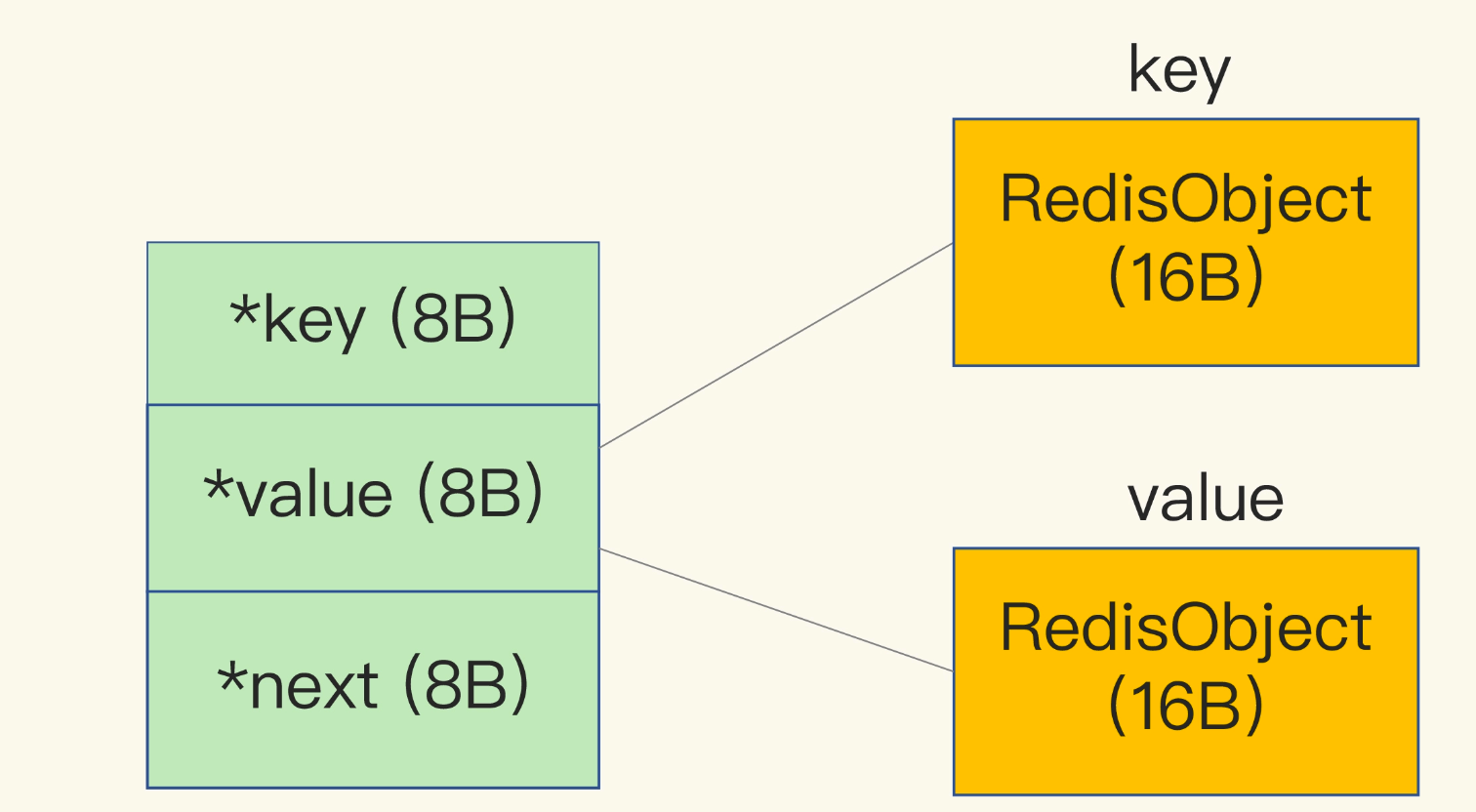
但是,这三个指针只有24字节,为什么会占用了32字节呢?这就要提到Redis使用的内存分配库jemalloc了。
jemalloc在分配内存时,会根据我们申请的字节数N,找一个比N大,但是最接近N的2的幂次数作为分配的空间,这样可以减少频繁分配的次数。
举个例子。如果你申请6字节空间,jemalloc实际会分配8字节空间;如果你申请24字节空间,jemalloc则会分配32字节。所以,在我们刚刚说的场景里,dictEntry结构就占用了32字节。
容量评估
http://www.redis.cn/redis_memory/
命令 : info memory
压缩列表省内存
数据类型使用的各种场景
聚合统计
set
排序统计
ZRANGEBYSCORE 比 list 要好
二值状态统计
Bitmap提供了GETBIT/SETBIT操作
1# 记录该用户8月3号已签到。
2SETBIT uid:sign:3000:202008 2 1
3# 检查该用户8月3日是否签到。
4GETBIT uid:sign:3000:202008 2
5# 统计该用户在8月份的签到次数。
6BITCOUNT uid:sign:3000:202008
基数统计
基数统计就是指统计一个集合中不重复的元素个数。 统计网页的UV。
用set 很吃内存
Redis中,每个 HyperLogLog只需要花费 12 KB 内存,就可以计算接近 2^64 个元素的基数。你看,和元素越多就越耗费内存的Set和Hash类型相比,HyperLogLog就非常节省空间。
在统计UV时,你可以用PFADD命令(用于向HyperLogLog中添加新元素)把访问页面的每个用户都添加到HyperLogLog中。
1PFADD page1:uv user1 user2 user3 user4 user5
接下来,就可以用PFCOUNT命令直接获得page1的UV值了,这个命令的作用就是返回HyperLogLog的统计结果。
1PFCOUNT page1:uv
如何在Redis中保存时间序列数据?
基于Hash和Sorted Set保存时间序列数据
1hset key_name 202008030905 value
2hset key_name 202008030906 value
3hget key_name 202008030906
Hash类型有个短板:它并不支持对数据进行范围查询。
Sorted Set , 分数就是时间, 利用ZRANGEBYSCORE 可以进行范围查询。
同时使用Hash和Sorted Set,可以满足单个时间点和一个时间范围内的数据查询需求
原子性保证
如何保证写入Hash和Sorted Set是一个原子性的操作呢?
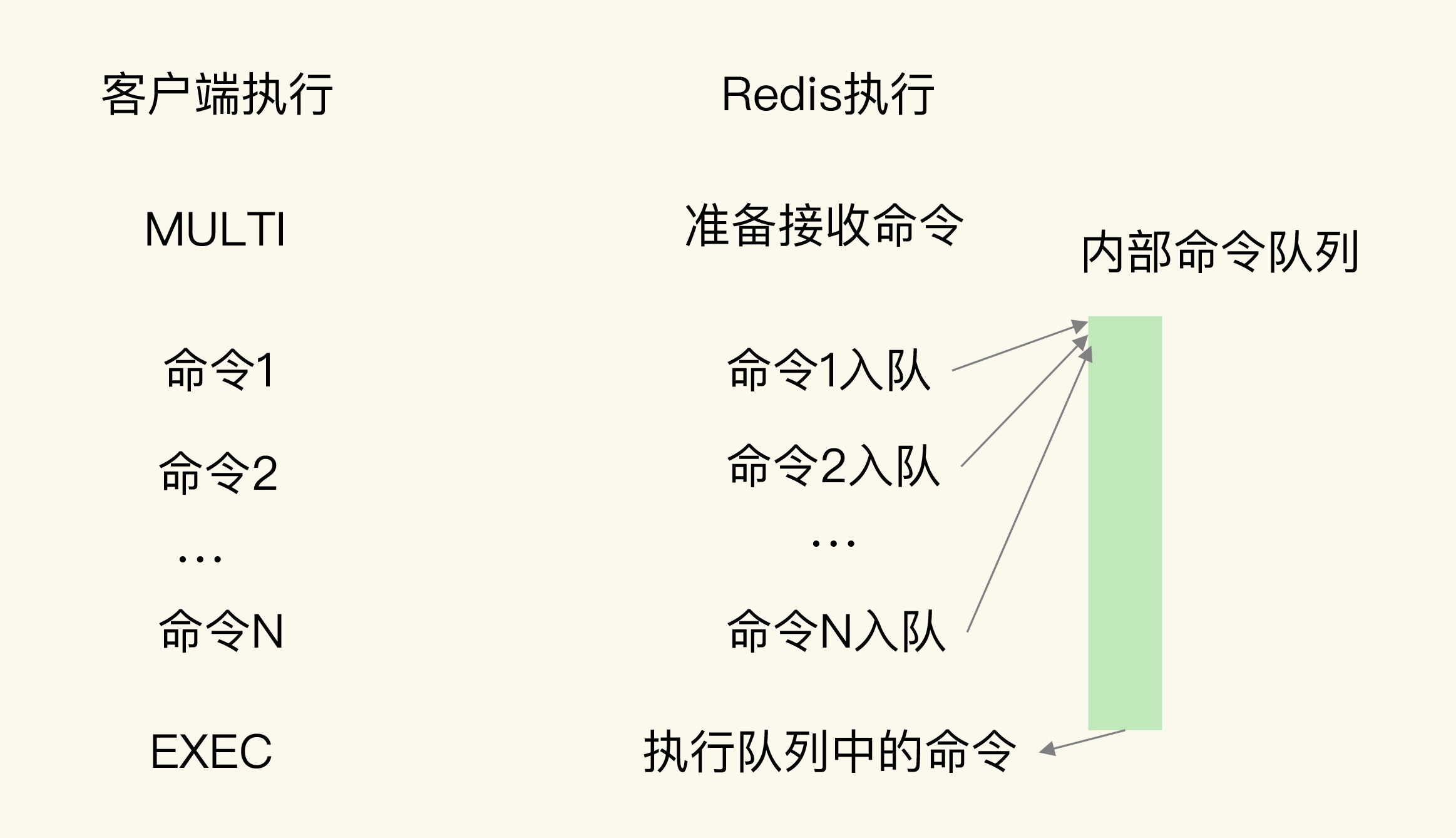
那Redis是怎么保证原子性操作的呢?这里就涉及到了Redis用来实现简单的事务的MULTI和EXEC命令。当多个命令及其参数本身无误时,MULTI和EXEC命令可以保证执行这些命令时的原子性
1127.0.0.1:6379> MULTI
2OK
3
4127.0.0.1:6379> HSET device:temperature 202008030911 26.8
5QUEUED
6
7127.0.0.1:6379> ZADD device:temperature 202008030911 26.8
8QUEUED
9
10127.0.0.1:6379> EXEC
111) (integer) 1
122) (integer) 1
Redis收到了客户端执行的MULTI命令。然后,客户端再执行HSET和ZADD命令后,Redis返回的结果为“QUEUED”,表示这两个命令暂时入队,先不执行;执行了EXEC命令后,HSET命令和ZADD命令才真正执行,并返回成功结果(结果值为1)
消息队列 (忽略)
可以有更专业的,当然非高并发,小型项目,数据没那么重要的,也是可以用redis 的。
异步机制:如何避免单线程模型的阻塞
集合元素全量查询操作HGETALL、SMEMBERS,以及集合的聚合统计操作,例如求交、并和差集。这些操作可以作为Redis的第一个阻塞点:集合全量查询和聚合操作。
bigkey删除操作就是Redis的第二个阻塞点
Redis的第三个阻塞点:清空数据库。
第四个阻塞点了:AOF日志同步写。
主从节点交互时的阻塞点,对于从库来说,它在接收了RDB文件后,需要使用FLUSHDB命令清空当前数据库,这就正好撞上了刚才我们分析的第三个阻塞点。
此外,从库在清空当前数据库后,还需要把RDB文件加载到内存,这个过程的快慢和RDB文件的大小密切相关,RDB文件越大,加载过程越慢,所以,加载RDB文件就成为了Redis的第五个阻塞点。
除了“集合全量查询和聚合操作”和“从库加载RDB文件”,其他三个阻塞点涉及的操作都不在关键路径上,所以,我们可以使用Redis的异步子线程机制来实现bigkey删除,清空数据库,以及AOF日志同步写。
当收到键值对删除和清空数据库的操作时,惰性删除(lazy free)
和惰性删除类似,当AOF日志配置成everysec选项后,主线程会把AOF写日志操作封装成一个任务,也放到任务队列中。后台子线程读取任务后,开始自行写入AOF日志,这样主线程就不用一直等待AOF日志写完了。
键值对删除:当你的集合类型中有大量元素(例如有百万级别或千万级别元素)需要删除时,我建议你使用UNLINK命令。
清空数据库:可以在FLUSHDB和FLUSHALL命令后加上ASYNC选项,这样就可以让后台子线程异步地清空数据库,如下所示:
旁路缓存
1String cacheKey = “productid_11010003”;
2String cacheValue = redisCache.get(cacheKey);
3//缓存命中
4if ( cacheValue != NULL)
5 return cacheValue;
6//缓存缺失
7else
8 cacheValue = getProductFromDB();
9 redisCache.put(cacheValue) //缓存更新
缓存的类型
按照Redis缓存是否接受写请求,我们可以把它分成只读缓存和读写缓存。
只读缓存
先读redis, 修改数据则是增删改 数据库,然后 删除redis读缓存
读写缓存
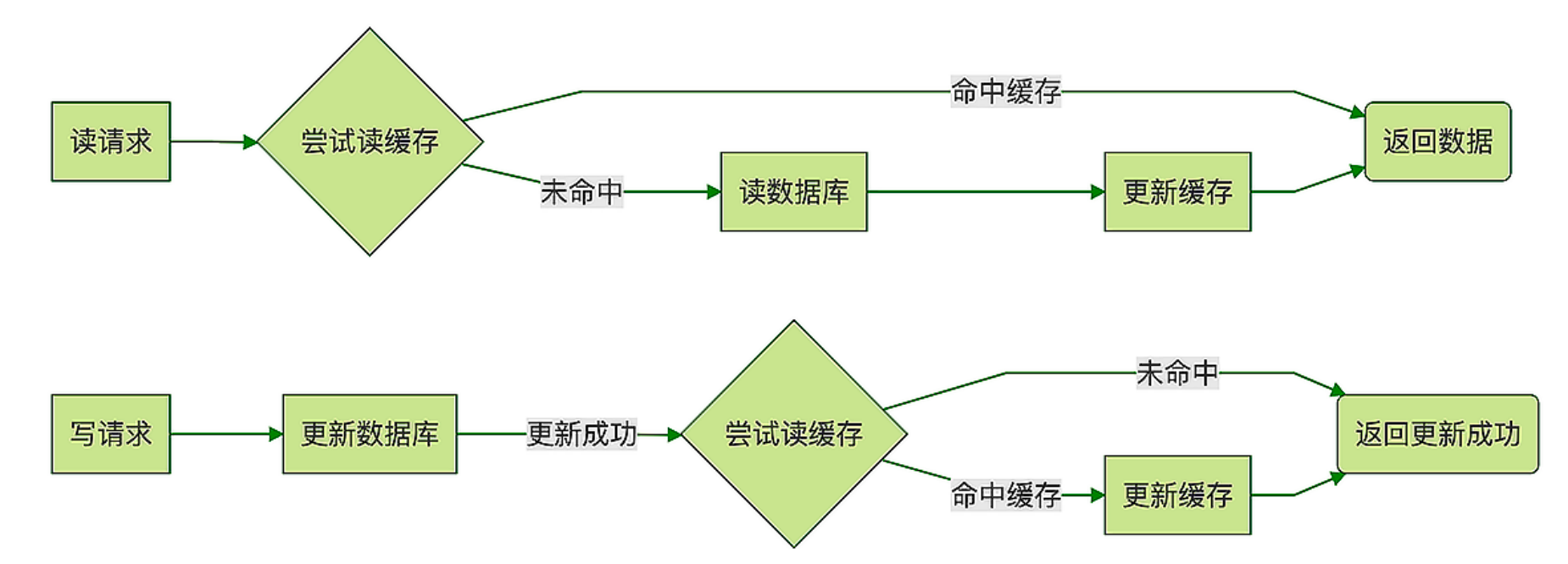
对于读写缓存来说,除了读请求会发送到缓存进行处理(直接在缓存中查询数据是否存在),所有的写请求也会发送到缓存,在缓存中直接对数据进行增删改操作。此时,得益于Redis的高性能访问特性,数据的增删改操作可以在缓存中快速完成,处理结果也会快速返回给业务应用,这就可以提升业务应用的响应速度。
但是,和只读缓存不一样的是,在使用读写缓存时,最新的数据是在Redis中,而Redis是内存数据库,一旦出现掉电或宕机,内存中的数据就会丢失。这也就是说,应用的最新数据可能会丢失,给应用业务带来风险。
根据业务应用对数据可靠性和缓存性能的不同要求,我们会有同步直写和异步写回两种策略。
同步直写
同步直写是指,写请求发给缓存的同时,也会发给后端数据库进行处理,等到缓存和数据库都写完数据,才给客户端返回。
会降低缓存的访问性能
异步写回策略
优先考虑了响应延迟 .就是先修改redis, 后慢找时间(可能是缓存满了) 取 回写db。
缓存满了怎么办
1CONFIG SET maxmemory 4gb
Redis缓存有哪些淘汰策略
- 不进行数据淘汰的策略,只有noeviction这一种。
- 在设置了过期时间的数据中进行淘汰,包括volatile-random、volatile-ttl、volatile-lru、volatile-lfu(Redis 4.0后新增)四种。
- 在所有数据范围内进行淘汰,包括allkeys-lru、allkeys-random、allkeys-lfu(Redis 4.0后新增)三种。
volatile-ttl在筛选时,会针对设置了过期时间的键值对,根据过期时间的先后进行删除,越早过期的越先被删除。
volatile-random就像它的名称一样,在设置了过期时间的键值对中,进行随机删除。
volatile-lru会使用LRU算法筛选设置了过期时间的键值对。
volatile-lfu会使用LFU算法选择设置了过期时间的键值对。
db 缓存一致性问题
核心问题
读写有并发,写写有并发, 无法保障happens before。
使用删除缓存的方式的问题
删除缓存会出现,cache miss (高并发cache miss 会出问题) , 用set
方案一(setex,setnx,加异步延迟队列)
读/写同时操作:
读操作,读缓存,缓存miss
读操作,读db,读取到数据
写操作,读db,读取到数据
写操作,更新db数据
写操作 set cache (可异步job操作,redis 可以使用setex操作)
读操作,add 操作数据回写缓存(可job 异步操作,redis 可以使用setnx 操作)
注意:写操作使用sex (sex. Ex) 覆盖写缓存,读操作使用add 回写miss数据(setnx),从而保证写操作的最新数据不会被读操作的回写数据覆盖。
写写操作(如后台多人操作),这样还是出现问题,订阅mysql binglog , 延迟几秒后 更新缓存
使用redis的setex,setnx避免读写并发, 利用订阅binlog做延迟队列 更新缓存解决写写并发操作。
方案2:数据库与缓存更新与读取操作进行异步串行化
更新数据的时候,将操作任务,发送到一个队列中。读取数据的时候,如果发现数据不在缓存中,那么将重新读取数据+更新缓存的操作任务,也发送同一个队列中。 每个队列可以对应多个消费者,每个队列拿到对应的消费者,然后一条一条的执行
缓存雪崩、击穿、穿透
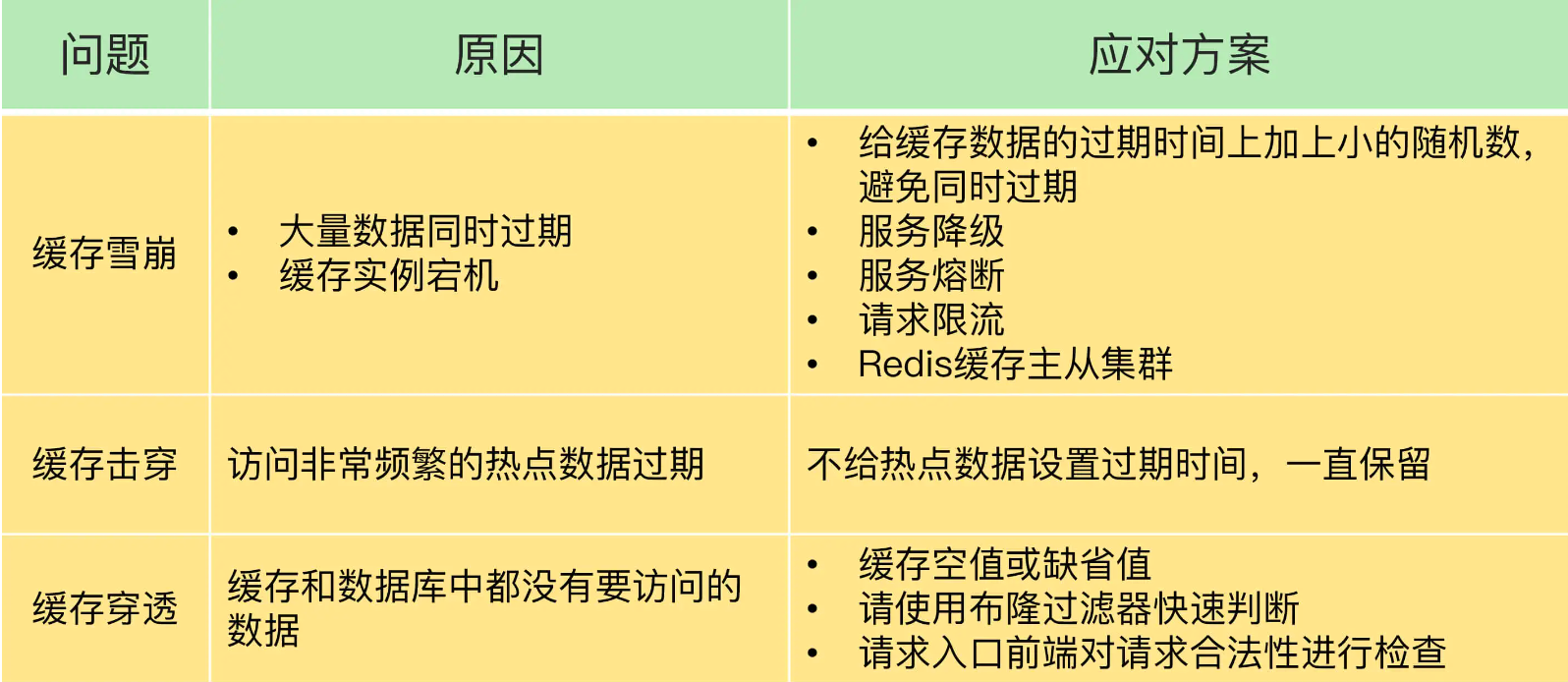
击穿,加分布式锁,访问数据库
布隆过滤器
https://blog.csdn.net/wuhuayangs/article/details/121830094
数据结构 bitmap 或 二进制位数组 。
能判断元素一定不存在,但是不能判断元素一定存在,因为有hash碰撞。