学习理解协程的运行机制与调度器原理。
为什么要有协程?
进程用来分配内存空间
线程用来分配cpu时间
线程是协程的资源,协程使用线程这个资源
协程用来精细利用线程
协程的本质是一段包含运行状态的程序
协程一般被认为是轻量级的线程。线程是操作系统资源调度的基本单位,但操作系统却感知不到协程的存在,协程的管理依赖 Go 语言运行时自身提供的调度器。因此准确地说,Go 语言中的协程是从属于某一个线程的,只有协程和实际线程绑定,才有执行的机会。
线程切换的速度大约为1~2 微秒,Go 语言中协程切换的速度则比它快数倍,为0.2 微秒左右。不过上下文切换的速度受到诸多因素的影响,会根据实际情况有所波动。
线程的栈的大小一般是在创建时指定的。为了避免出现栈溢出(Stack Overflow)的情况,默认的栈会相对较大(例如2MB),这意味着每创建 1000 个线程就需要消耗2GB 的虚拟内存,大大限制了可以创建的线程的数量(64 位的虚拟内存地址空间已经让这种限制变得不太严重)。而Go语言中的协程栈默认为2KB,所以在实践中,我们经常会看到成千上万的协程存在。
协程的底层结构
runtime中协成本质是一个g 结构体 , 重要的几个字段如下。
- stack :堆栈地址
- 低地址
- 高地址
- sched -> gobuf结构体 (目前协程的运行现场)
- sp 运行到哪个函数栈 , 保存CPU 的rsp 寄存器的值
- pc 运行到这个函数的哪一行代码 , 保存CPU 的rip 寄存器的值
- atomicstatus 协程的状态
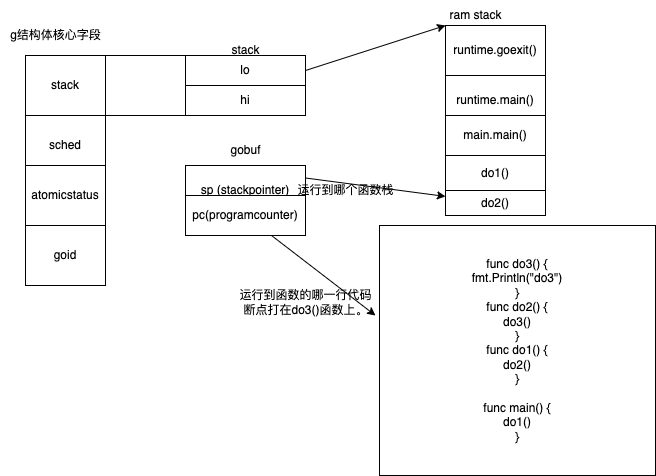
源码见runtime2.go
1// Stack describes a Go execution stack.
2// The bounds of the stack are exactly [lo, hi),
3// with no implicit data structures on either side.
4type stack struct {
5 lo uintptr // 低地址
6 hi uintptr // 高地址
7}
8
9
10type gobuf struct {
11// The offsets of sp, pc, and g are known to (hard-coded in) libmach.
12//
13// ctxt is unusual with respect to GC: it may be a
14// heap-allocated funcval, so GC needs to track it, but it
15// needs to be set and cleared from assembly, where it's
16// difficult to have write barriers. However, ctxt is really a
17// saved, live register, and we only ever exchange it between
18// the real register and the gobuf. Hence, we treat it as a
19// root during stack scanning, which means assembly that saves
20// and restores it doesn't need write barriers. It's still
21// typed as a pointer so that any other writes from Go get
22// write barriers.
23 sp uintptr // sp 运行到哪个函数栈 , 保存CPU 的rsp 寄存器的值
24 pc uintptr // pc 运行到 这个函数的 哪一行代码 , 保存CPU 的rip 寄存器的值
25 g guintptr // 记录当前这个gobuf 对象属于哪个Goroutine
26 ctxt unsafe.Pointer
27 ret uintptr //保存系统调用的返回值
28 lr uintptr
29 bp uintptr // for framepointer-enabled architectures 保存CPU 的rbp 寄存器的值
30}
31
32
33type g struct {
34 // Stack parameters.
35 // stack describes the actual stack memory: [stack.lo, stack.hi).
36 // stackguard0 is the stack pointer compared in the Go stack growth prologue.
37 // It is stack.lo+StackGuard normally, but can be StackPreempt to trigger a preemption.
38 // stackguard1 is the stack pointer compared in the C stack growth prologue.
39 // It is stack.lo+StackGuard on g0 and gsignal stacks.
40 // It is ~0 on other goroutine stacks, to trigger a call to morestackc (and crash).
41 stack stack // offset known to runtime/cgo 堆栈地址
42 stackguard0 uintptr // offset known to liblink
43 stackguard1 uintptr // offset known to liblink
44
45 _panic *_panic // innermost panic - offset known to liblink
46 _defer *_defer // innermost defer
47 m *m // current m; offset known to arm liblink
48 sched gobuf // 目前协程的运行现场
49 syscallsp uintptr // if status==Gsyscall, syscallsp = sched.sp to use during gc
50 syscallpc uintptr // if status==Gsyscall, syscallpc = sched.pc to use during gc
51 stktopsp uintptr // expected sp at top of stack, to check in traceback
52 param unsafe.Pointer // passed parameter on wakeup
53 atomicstatus uint32 // 协程的状态
54 stackLock uint32 // sigprof/scang lock; TODO: fold in to atomicstatus
55 goid int64 //协成id号
56 schedlink guintptr
57 waitsince int64 // approx time when the g become blocked
58 waitreason waitReason // if status==Gwaiting
59
60 preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
61 preemptStop bool // transition to _Gpreempted on preemption; otherwise, just deschedule
62 preemptShrink bool // shrink stack at synchronous safe point
63
64 // asyncSafePoint is set if g is stopped at an asynchronous
65 // safe point. This means there are frames on the stack
66 // without precise pointer information.
67 asyncSafePoint bool
68
69 paniconfault bool // panic (instead of crash) on unexpected fault address
70 gcscandone bool // g has scanned stack; protected by _Gscan bit in status
71 throwsplit bool // must not split stack
72 // activeStackChans indicates that there are unlocked channels
73 // pointing into this goroutine's stack. If true, stack
74 // copying needs to acquire channel locks to protect these
75 // areas of the stack.
76 activeStackChans bool
77 // parkingOnChan indicates that the goroutine is about to
78 // park on a chansend or chanrecv. Used to signal an unsafe point
79 // for stack shrinking. It's a boolean value, but is updated atomically.
80 parkingOnChan uint8
81
82 raceignore int8 // ignore race detection events
83 sysblocktraced bool // StartTrace has emitted EvGoInSyscall about this goroutine
84 sysexitticks int64 // cputicks when syscall has returned (for tracing)
85 traceseq uint64 // trace event sequencer
86 tracelastp puintptr // last P emitted an event for this goroutine
87 lockedm muintptr
88 sig uint32
89 writebuf []byte
90 sigcode0 uintptr
91 sigcode1 uintptr
92 sigpc uintptr
93 gopc uintptr // pc of go statement that created this goroutine
94 ancestors *[]ancestorInfo // ancestor information goroutine(s) that created this goroutine (only used if debug.tracebackancestors)
95 startpc uintptr // pc of goroutine function
96 racectx uintptr
97 waiting *sudog // sudog structures this g is waiting on (that have a valid elem ptr); in lock order
98 cgoCtxt []uintptr // cgo traceback context
99 labels unsafe.Pointer // profiler labels
100 timer *timer // cached timer for time.Sleep
101 selectDone uint32 // are we participating in a select and did someone win the race?
102
103 // Per-G GC state
104
105 // gcAssistBytes is this G's GC assist credit in terms of
106 // bytes allocated. If this is positive, then the G has credit
107 // to allocate gcAssistBytes bytes without assisting. If this
108 // is negative, then the G must correct this by performing
109 // scan work. We track this in bytes to make it fast to update
110 // and check for debt in the malloc hot path. The assist ratio
111 // determines how this corresponds to scan work debt.
112 gcAssistBytes int64
113}
线程的抽象
runtime中操作系统线程的抽象为m结构体
runtime2.go
1type m struct{
2 g0 *g // goroutine with scheduling stack g0协程,操作调度器
3 p puintptr // m当前对应的逻辑处理器P
4 curg *g //当前m绑定的用户协程g , 目前线程运行的g
5 mOS //操作系统线程信息
6 tls [tlsSlots]uintptr // thread-local storage (for x86 extern register) 线程局部存储
7 ...
8}
核心字段
g0 :g0协程,操作调度器
p : m当前对应的逻辑处理器P
curg :current g 目前线程运行的g
mOS :操作系统线程信息
线程本地存储的数据实际是结构体m中 m.tls 的地址,同时,m.tls[0]会存储当前线程正在运行的协程 g 的地址,因此在任意一个线程内部,通过线程本地存储,都可以在任意时刻获取绑定在当前线程上的协程g、结构体m、逻辑处理器P、特殊协程g0等的信息。
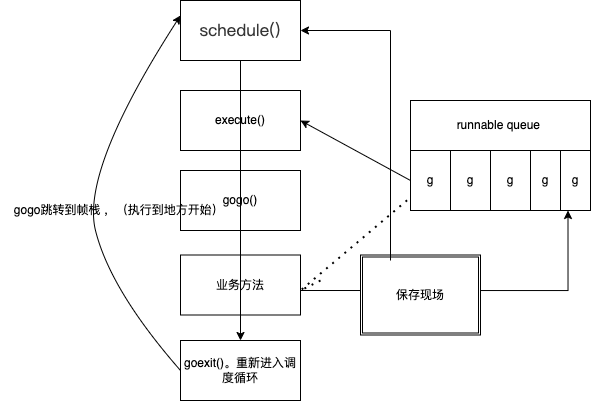
协程是怎么运行的
0.x 版本 是 单线程循环调度
先看大致流程图。
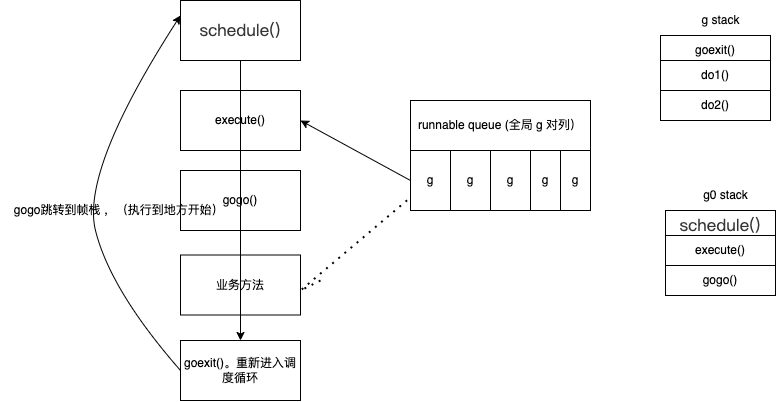
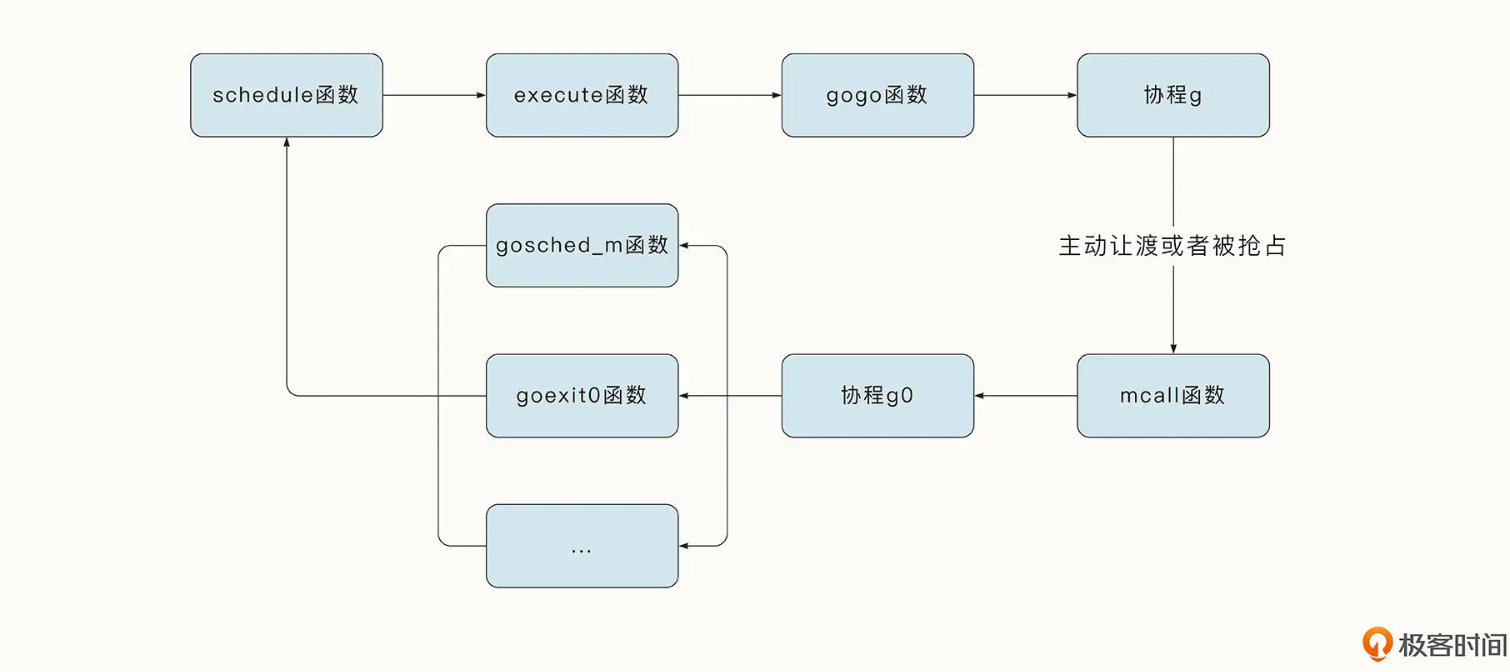
线程开始可以理解为 拿g0 栈开始的
runtime/proc.go
- schedule() 函数处理的是具体的调度策略,也就是选择下一个要执行的协程
- execute() execute 函数执行的是一些具体的状态转移、协程g 与结构体m 之间的绑定等操作;选择要调度的g。
- gogo() gogo函数是与操作系统有关的函数,用于完成栈的切换以及恢复 CPU 寄存器。执行完这一步之后,协程就会切换到协程 g 去执行
- goexit() 如果协程已经退出,则执行 goexit 函数,将协程 g 放入 p 的freeg 队列,方便下次重用。
- gosched_m() 如果是用户调用 Gosched 函数主动让渡执行权,就会执行gosched_m 函数
执行完毕后,运行时再次调用schedule 函数开始新一轮的调度循环,从而形成一个完整的闭环,循环往复。
1func schedule()
2
3
4
5// One round of scheduler: find a runnable goroutine and execute it.
6// Never returns.
7func schedule() {
8 _g_ := getg()
9
10 if _g_.m.locks != 0 {
11 throw("schedule: holding locks")
12 }
13
14 if _g_.m.lockedg != 0 {
15 stoplockedm()
16 execute(_g_.m.lockedg.ptr(), false) // Never returns.
17 }
18
19 // We should not schedule away from a g that is executing a cgo call,
20 // since the cgo call is using the m's g0 stack.
21 if _g_.m.incgo {
22 throw("schedule: in cgo")
23 }
24
25top:
26 pp := _g_.m.p.ptr()
27 pp.preempt = false
28
29 if sched.gcwaiting != 0 {
30 gcstopm()
31 goto top
32 }
33 if pp.runSafePointFn != 0 {
34 runSafePointFn()
35 }
36
37 // Sanity check: if we are spinning, the run queue should be empty.
38 // Check this before calling checkTimers, as that might call
39 // goready to put a ready goroutine on the local run queue.
40 if _g_.m.spinning && (pp.runnext != 0 || pp.runqhead != pp.runqtail) {
41 throw("schedule: spinning with local work")
42 }
43
44 checkTimers(pp, 0)
45
46 var gp *g // gp 要即将运行的协程
47 var inheritTime bool
48
49 // Normal goroutines will check for need to wakeP in ready,
50 // but GCworkers and tracereaders will not, so the check must
51 // be done here instead.
52 tryWakeP := false
53 if trace.enabled || trace.shutdown {
54 gp = traceReader()
55 if gp != nil {
56 casgstatus(gp, _Gwaiting, _Grunnable)
57 traceGoUnpark(gp, 0)
58 tryWakeP = true
59 }
60 }
61 if gp == nil && gcBlackenEnabled != 0 {
62 gp = gcController.findRunnableGCWorker(_g_.m.p.ptr())
63 tryWakeP = tryWakeP || gp != nil
64 }
65 if gp == nil {
66 // Check the global runnable queue once in a while to ensure fairness.
67 // Otherwise two goroutines can completely occupy the local runqueue
68 // by constantly respawning each other.
69 if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
70 lock(&sched.lock)
71 gp = globrunqget(_g_.m.p.ptr(), 1)
72 unlock(&sched.lock)
73 }
74 }
75 if gp == nil {
76 gp, inheritTime = runqget(_g_.m.p.ptr())
77 // We can see gp != nil here even if the M is spinning,
78 // if checkTimers added a local goroutine via goready.
79 }
80 if gp == nil {
81 gp, inheritTime = findrunnable() // blocks until work is available
82 }
83
84 // This thread is going to run a goroutine and is not spinning anymore,
85 // so if it was marked as spinning we need to reset it now and potentially
86 // start a new spinning M.
87 if _g_.m.spinning {
88 resetspinning()
89 }
90
91 if sched.disable.user && !schedEnabled(gp) {
92 // Scheduling of this goroutine is disabled. Put it on
93 // the list of pending runnable goroutines for when we
94 // re-enable user scheduling and look again.
95 lock(&sched.lock)
96 if schedEnabled(gp) {
97 // Something re-enabled scheduling while we
98 // were acquiring the lock.
99 unlock(&sched.lock)
100 } else {
101 sched.disable.runnable.pushBack(gp)
102 sched.disable.n++
103 unlock(&sched.lock)
104 goto top
105 }
106 }
107
108 // If about to schedule a not-normal goroutine (a GCworker or tracereader),
109 // wake a P if there is one.
110 if tryWakeP {
111 wakep()
112 }
113 if gp.lockedm != 0 {
114 // Hands off own p to the locked m,
115 // then blocks waiting for a new p.
116 startlockedm(gp)
117 goto top
118 }
119
120 execute(gp, inheritTime)
121}
122
123
124
125//go:yeswritebarrierrec
126func execute(gp *g, inheritTime bool) {
127 _g_ := getg()
128
129 // Assign gp.m before entering _Grunning so running Gs have an
130 // M.
131 _g_.m.curg = gp
132 gp.m = _g_.m
133 casgstatus(gp, _Grunnable, _Grunning)
134 gp.waitsince = 0
135 gp.preempt = false
136 gp.stackguard0 = gp.stack.lo + _StackGuard
137 if !inheritTime {
138 _g_.m.p.ptr().schedtick++
139 }
140
141 // Check whether the profiler needs to be turned on or off.
142 hz := sched.profilehz
143 if _g_.m.profilehz != hz {
144 setThreadCPUProfiler(hz)
145 }
146 if trace.enabled {
147 // GoSysExit has to happen when we have a P, but before GoStart.
148 // So we emit it here.
149 if gp.syscallsp != 0 && gp.sysblocktraced {
150 traceGoSysExit(gp.sysexitticks)
151 }
152 traceGoStart()
153 }
154 gogo(&gp.sched) //汇编实现的
155}
156
157
158//gogo 汇编
159// func gogo(buf *gobuf)
160// restore state from Gobuf; longjmp
161TEXT runtime·gogo(SB), NOSPLIT, $16-8
162 MOVQ buf+0(FP), BX // gobuf
163 MOVQ gobuf_g(BX), DX
164 MOVQ 0(DX), CX // make sure g != nil
165 get_tls(CX)
166 MOVQ DX, g(CX)
167 MOVQ gobuf_sp(BX), SP // restore SP
168 MOVQ gobuf_ret(BX), AX
169 MOVQ gobuf_ctxt(BX), DX
170 MOVQ gobuf_bp(BX), BP
171 MOVQ $0, gobuf_sp(BX) // clear to help garbage collector
172 MOVQ $0, gobuf_ret(BX)
173 MOVQ $0, gobuf_ctxt(BX)
174 MOVQ $0, gobuf_bp(BX)
175 MOVQ gobuf_pc(BX), BX
176 JMP BX //跳转到 帧栈 ,(执行到地方开始)
177
178
179
180
181 //goexit
182 // The top-most function running on a goroutine
183// returns to goexit+PCQuantum.
184TEXT runtime·goexit(SB),NOSPLIT,$0-0
185 BYTE $0x90 // NOP
186 CALL runtime·goexit1(SB) // does not return
187 // traceback from goexit1 must hit code range of goexit
188 BYTE $0x90 // NO
189
190
191 runtime.proc.go
192
193 // Finishes execution of the current goroutine.
194func goexit1() {
195 if raceenabled {
196 racegoend()
197 }
198 if trace.enabled {
199 traceGoEnd()
200 }
201 mcall(goexit0)
202}
203
204
205
206func mcall(fn func(*g))
207
208// systemstack runs fn on a system stack.
209// If systemstack is called from the per-OS-thread (g0) stack, or
210// if systemstack is called from the signal handling (gsignal) stack,
211// systemstack calls fn directly and returns.
212// Otherwise, systemstack is being called from the limited stack
213// of an ordinary goroutine. In this case, systemstack switches
214// to the per-OS-thread stack, calls fn, and switches back.
215// It is common to use a func literal as the argument, in order
216// to share inputs and outputs with the code around the call
217// to system stack:
218//
219// ... set up y ...
220// systemstack(func() {
221// x = bigcall(y)
222// })
223// ... use x ...
224
225
226// goexit0 ,又到了 schedule
227// goexit continuation on g0.
228func goexit0(gp *g) {
229 _g_ := getg()
230
231 casgstatus(gp, _Grunning, _Gdead)
232 if isSystemGoroutine(gp, false) {
233 atomic.Xadd(&sched.ngsys, -1)
234 }
235 gp.m = nil
236 locked := gp.lockedm != 0
237 gp.lockedm = 0
238 _g_.m.lockedg = 0
239 gp.preemptStop = false
240 gp.paniconfault = false
241 gp._defer = nil // should be true already but just in case.
242 gp._panic = nil // non-nil for Goexit during panic. points at stack-allocated data.
243 gp.writebuf = nil
244 gp.waitreason = 0
245 gp.param = nil
246 gp.labels = nil
247 gp.timer = nil
248
249 if gcBlackenEnabled != 0 && gp.gcAssistBytes > 0 {
250 // Flush assist credit to the global pool. This gives
251 // better information to pacing if the application is
252 // rapidly creating an exiting goroutines.
253 scanCredit := int64(gcController.assistWorkPerByte * float64(gp.gcAssistBytes))
254 atomic.Xaddint64(&gcController.bgScanCredit, scanCredit)
255 gp.gcAssistBytes = 0
256 }
257
258 dropg()
259
260 if GOARCH == "wasm" { // no threads yet on wasm
261 gfput(_g_.m.p.ptr(), gp)
262 schedule() // never returns
263 }
264
265 if _g_.m.lockedInt != 0 {
266 print("invalid m->lockedInt = ", _g_.m.lockedInt, "\n")
267 throw("internal lockOSThread error")
268 }
269 gfput(_g_.m.p.ptr(), gp)
270 if locked {
271 // The goroutine may have locked this thread because
272 // it put it in an unusual kernel state. Kill it
273 // rather than returning it to the thread pool.
274
275 // Return to mstart, which will release the P and exit
276 // the thread.
277 if GOOS != "plan9" { // See golang.org/issue/22227.
278 gogo(&_g_.m.g0.sched)
279 } else {
280 // Clear lockedExt on plan9 since we may end up re-using
281 // this thread.
282 _g_.m.lockedExt = 0
283 }
284 }
285 schedule()
286}
g1.0 多线程循环
操作系统并不知道g 的存在
加锁向全局队列拿goroutine 。
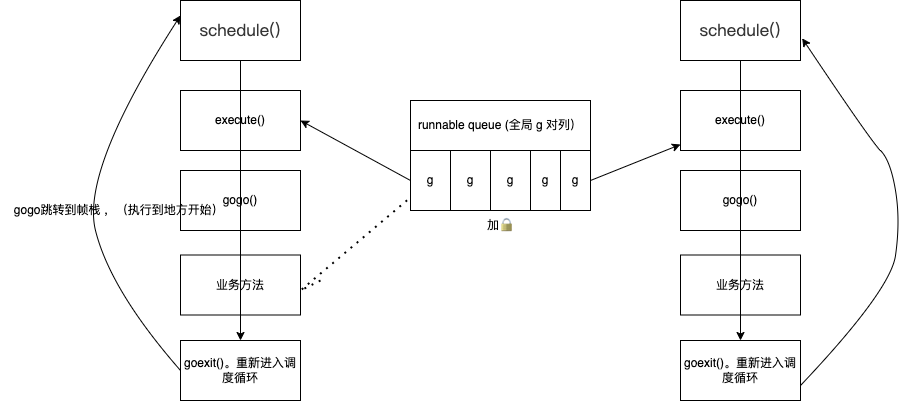
为什么要gmp调度模型
- 单线程顺序执行goroutine 无法并发。
- 多线程并发时,会抢夺协程队列的全局锁
- 多线程 从 全局 go队列 拿 go 要加全局锁 ,这种 性能不太好 ,会造成频繁的锁冲突
协程的本质是一个g结构体
g结构体记录了协程栈,pc信息(程序计数器信息)
线程执行标准调度循环,执行协程
本地队列
m每次从全局 抓n个 go过来 ,这样锁冲突就少了。
1type p struct {
2 // 使用数组实现的循环队列
3 runq [256]guintptr // goroutine数组
4 runnext guintptr // 运行下一个 goroutine 的 地址
5 m muintptr // back-link to associated m (nil if idle)
6 // Queue of runnable goroutines. Accessed without lock.
7 runqhead uint32
8 runqtail uint32
9}
Go 语言调度器将运行队列分为局部运行队列与全局运行队列。局部运行队列是每个P 特有的长度为 256 的数组。这个数组模拟了一个循环队列,其中,runqhead 标识了循环队列的开头,runqtail 标识了循环队列的末尾。每次将 G 放入本地队列时,都是从循环队列的末尾插入,而获取 G 时则是从循环队列的头部获取。
除此之外,在每个 P 内部还有一个特殊的 runnext 字段,它标识了下一个要执行的协程。如果runnext 不为空,则会直接执行当前 runnext 指向的协程,不会再去runq 数组中寻找。
p 的作用
m与g 的中介(送料器)
p持有一些g,使得每次获取不需要从全局找,本地队列找
大大减少并发冲突的情况
通过p结构体,达到缓存g的目的
p本质上是个一个g的本地队列,避免全局并发
本地队列拿不到 runtime/proc.go runqget() 就 globrunqget() 全局队列拿一批, 如果全局也没有,从其他p 上 偷一些过来。
-
先本地队列拿
-
再全局队列拿
-
再其他p地方窃取 (steal work)(增强线程的利用率)
窃取式工作分配机制能够更加充分利用线程资源
新建协程
- 随机寻找一个P
- 将新协程放入P的 runnext(插队)
- 如果P本地队列满了,放入全局队列
上述解决了 多线程并发时,抢夺协程队列的全局锁 问题 (也就是为什么要有 gpm 调度模型)
如何实现协程并发?
协程顺序执行,无法并发的问题
(线程会被卡主,如果一直等待协程运行结束的话)
协程饥饿问题
保存现场, 到循环开头
可以放回去,也可以休眠
全局队列饥饿问题
如果本地队列 (很多p) 都有个“重”的goroutine (小循环) , 那么全局队列可能就产生饥饿问题。 解决方法:
本地队列会时不时从全部队列拿 goroutine 。(每执行61次 线程循环 就会去全局队列拿一个goroutine)
1if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
2 lock(&sched.lock)
3 // 从全局运行队列中获取1 个G
4 gp = globrunqget(_g_.m.p.ptr(), 1)
5 unlock(&sched.lock)
6}
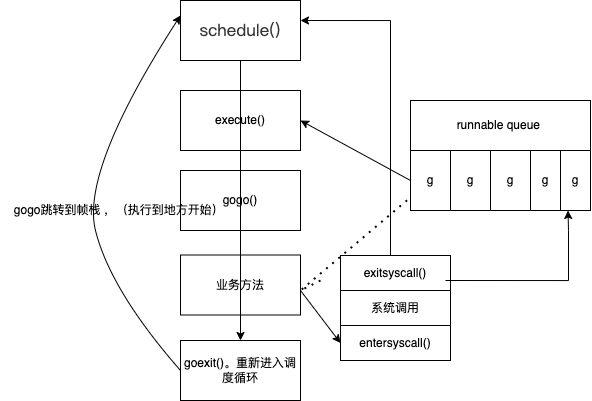
协程切换时机
都是切换到g0重新调度
- 系统调用完成时
- 主动挂起 gopark()
- time.Sleep() 底层也是调了 gopark()
- go park 最终是 调 mcall() 这个就是让他重新到g0栈的schedule
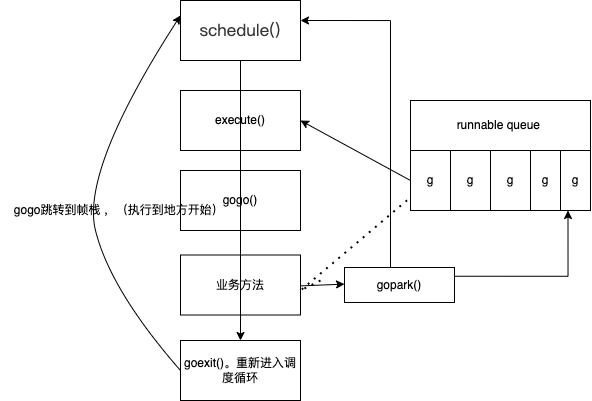
小结
- 如果协程顺序执行,会有饥饿问题
- 协程执行中间,将协程挂起,执行其他协程
- 完成系统调用时挂起,也可以主动挂起
- 防止全局队列饥饿,本地队列随机抽取全局队列
强占式调度
为了让每个协程都有执行的机会,并且最大化利用 CPU 资源,Go 语言在初始化时会启动一个特殊的线程来执行系统监控任务。
系统监控在一个独立的 M 上运行,不用绑定逻辑处理器 P,系统监控会每隔 10ms 检测一下有没有准备就绪的网络协程,如果有就放置到全局队列中。和抢占调度相关的是,系统监控服务会判断当前协程是否运行时间过长,或是否处于系统调用阶段,如果是, 则会抢占当前 G 的执行。
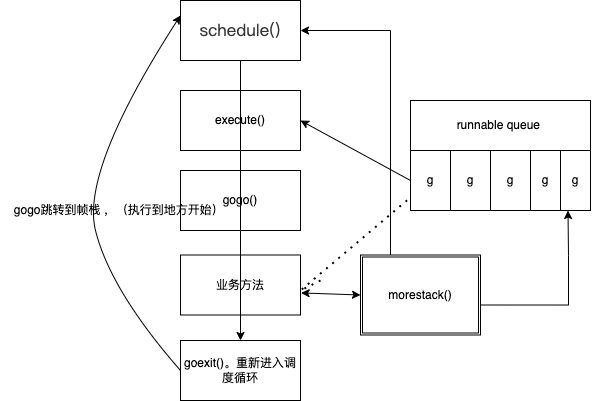
基于协作的抢占式调度 runtime.morestack()
1func do1(){
2 // runtime.morestack() 编译器会执行,方法前都要加这个
3 do2()
4}
5func do2(){
6
7}
系统监控到Goroutine运行超过10ms,将g.stackguard0置为 Oxfffffade ,标记为抢占
每次再函数跳转的时候 (跳转前) 就会执行 runtime.morestack() (编译器插入进去的)
morestack本意是检测 协程栈是否有足够的空间,并且会做判断 是否被抢占的 操作。
执行morestack()时判断是否被抢占,如果抢占了(标记)就 回到schedule()
基于信号的抢占式调度
在Go 1.14 之前,虽然仍然有系统监控抢占时间过长的G,但是这种抢占的时机发生在函数调用阶段,因此没有办法解决对于死循环的抢占,就像下面这个例子一样:
1for{
2 i++
3}
为了解决这一问题,Go 1.14 之后引入了信号强制抢占的机制。
线程信号
- 操作系统中,有很多基于信号的底层通信方式
- 比如sigpipe、sigurg、sighup
- 线程可以注册对应信号的处理函数
- 注册sigurg信号的处理函数
- gc工作时,向目标线程发信号
基于信号的抢占式调度
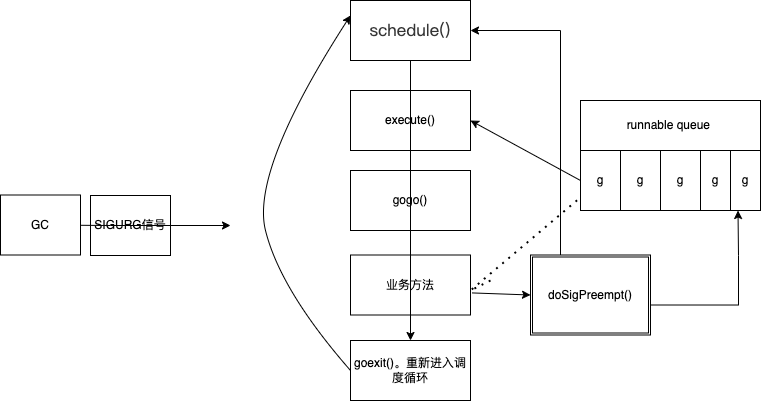
协程调度小结
基于系统调用和主动挂起(gopark),协程可能无法调度
基于协作的抢占式调度,业务主动调用morestack()
基于信号的抢占式调度:强制线程调用doSigPreempt() (gc工作 ,发信号) 如死循环处理。
协程太多的问题
- 文件打开数限制
- 内存限制
- 调度开销过大
处理协成太多的方案
- 优化业务逻辑 (减少时间)
- 利用channel的缓冲区
- 利用chanel 的缓存机制
- 启动协程前,向chanel发送一个结构体
- 协成结束,取出一个空结构体
- 协程池
- 慎用
- go语言的线程,已经相当于池化
- 二级池化会增加系统复杂度
- go语言初衷是希望协程即用即毁,不要池化
- 调整系统资源
太多的协程会给程运行带来性能和稳定性问题
牺牲并发特性,利用channel缓冲