go基本并发原语详解
锁基础之atomic操作
atomic是汇编实现
原子操作是一种硬件层面加锁的机制
cpu硬件
保证操作一个变量的时候,其他线程/协程无法访问
只能用于简单变量的简单操作
1atomic.CompareAndSwapInt32(&c,10,100)
2// 和下面是一个意思
3if c==10 {
4 c=100
5}
锁基础之sema锁
信号量锁/信号锁
核心是一个uint32值,含义是同时可并发的数量
每一个sema锁都对应一个SemaRoot结构体
sema.go
1type semaRoot struct {
2 lock mutex
3 treap *sudog // root of balanced tree of unique waiters. 等待者树
4 nwait uint32 // Number of waiters. Read w/o the lock. 等待者数
5}
6
7type sudog struct {
8 // The following fields are protected by the hchan.lock of the
9 // channel this sudog is blocking on. shrinkstack depends on
10 // this for sudogs involved in channel ops.
11
12 g *g
13
14 next *sudog
15 prev *sudog
16 elem unsafe.Pointer // data element (may point to stack)
17
18 // The following fields are never accessed concurrently.
19 // For channels, waitlink is only accessed by g.
20 // For semaphores, all fields (including the ones above)
21 // are only accessed when holding a semaRoot lock.
22
23 acquiretime int64
24 releasetime int64
25 ticket uint32
26
27 // isSelect indicates g is participating in a select, so
28 // g.selectDone must be CAS'd to win the wake-up race.
29 isSelect bool
30
31 // success indicates whether communication over channel c
32 // succeeded. It is true if the goroutine was awoken because a
33 // value was delivered over channel c, and false if awoken
34 // because c was closed.
35 success bool
36
37 parent *sudog // semaRoot binary tree
38 waitlink *sudog // g.waiting list or semaRoot
39 waittail *sudog // semaRoot
40 c *hchan // channel
41}
Semeroot 有一个平衡二叉树用于协程排队
1//获得锁 -1
2func semacquire1(addr *uint32, lifo bool, profile semaProfileFlags, skipframes int) {}
3
4//=0 获得锁失败
5func cansemacquire(addr *uint32) bool {
6 for {
7 v := atomic.Load(addr)
8 if v == 0 {
9 return false // =0 获得锁失败
10 }
11 if atomic.Cas(addr, v, v-1) {
12 return true //获得锁成功
13 }
14 }
15}
16
17//释放锁 +1
18func semrelease1(addr *uint32, handoff bool, skipframes int) {}
信号量值uint32 >0的时候
-
获取锁,uint32减1,获取成功
-
释放锁 :unit32+1 释放成功
信号量值uint32=0 的时候
- 获取锁:协程休眠,进入平衡二叉树等待(当队列用)
1//进入休眠
2// semacquire1
3goparkunlock(&root.lock, waitReasonSemacquire, traceEvGoBlockSync, 4+skipframes)
-
释放锁:从堆数(等待树)中取出一个协程,唤醒
-
sema锁退化成一个专用休眠队列
sema锁是runtime的常用工具
sema经常被用作休眠队列,如(sync.Mutex )
1// A Mutex must not be copied after first use.
2type Mutex struct {
3 state int32
4 sema uint32 //值=0 当等待队列用
5}
临界区
在并发编程中,如果程序中的一部分会被并发访问或修改,那么,为了避免并发访问导致的意想不到的结果,这部分程序需要被保护起来,这部分被保护起来的程序,就叫做临界区。
临界区就是一个被共享的资源,或者说是一个整体的一组共享资源,比如对数据库的访问、对某一个共享数据结构的操作、对一个 I/O 设备的使用、对一个连接池中的连接的调用,等等
使用互斥锁,限定临界区只能同时由一个线程持有
当临界区由一个线程持有的时候,其它线程如果想进入这个临界区,就会返回失败,或者是等待。直到持有的线程退出临界区,这些等待线程中的某一个才有机会接着持有这个临界区。
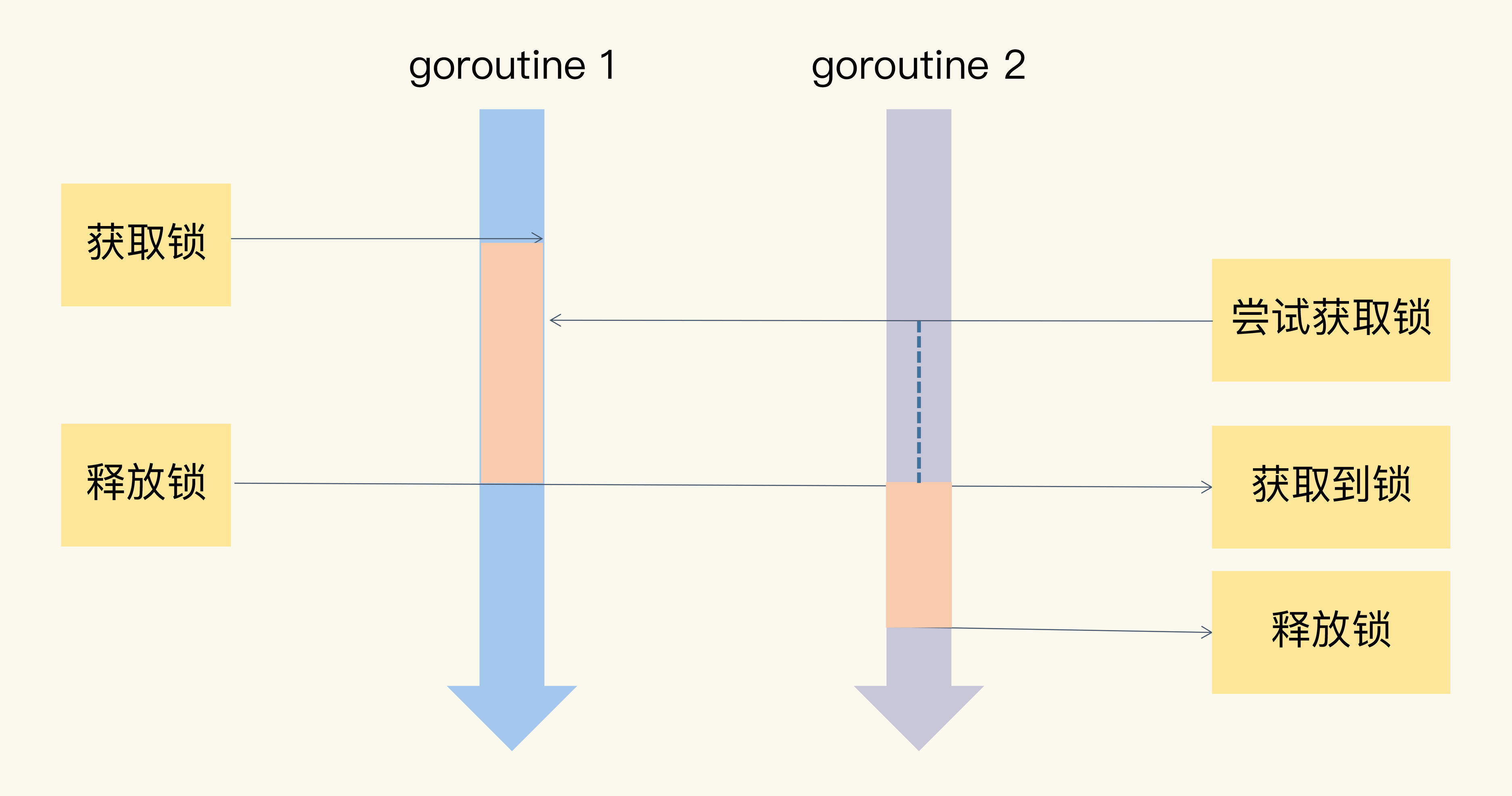
Mutex
当一个 goroutine 通过调用 Lock 方法获得了这个锁的拥有权后, 其它请求锁的 goroutine 就会阻塞在 Lock 方法的调用上,直到锁被释放并且自己获取到了这个锁的拥有权。
发现并发问题
1go run -race xxx.go
2go tool compile -S file.go #go语言查看汇编代码命令
谁申请谁释放
defer xx.Unlock()
1// A Mutex must not be copied after first use.
2type Mutex struct {
3 state int32
4 sema uint32 // 默认0
5}
state 分32位。
- locked 是否被锁住
- woken 唤醒标志
- starving 饥饿标志
- waitershift 等待着数量 (29位)

正常模式加锁
- 尝试cas 直接加锁(可能是多协程通过atomic 给 locked 改成1 )
- 若无法直接获取,进行多次自旋转尝试 (也是去改成1)
- 如果自旋失败,就会获取sema ,肯定会获取失败进入 sema 队列
- 多次尝试失败,进入sema队列休眠
正常模式解锁
- 尝试cas 直接解锁(最后一位改成0)
- 但是如果有协程在sema中休眠,唤醒一个协程
mutex正常模式:自旋加锁+sema休眠等待
mutext正常模式下,可能有锁饥饿问题
自旋加锁, 其实就是多给点机会。
饥饿问题
sema等待队列中释放出来的锁 也要和新的goroutine 去竞争 locked标志位, 去改 locked = 1,那么很可能一个goroutine长时间获得不到锁。
饥饿模式
starving 标记=1
- 当前协程等待锁的时间超过了1ms(任何协程),切换到饥饿模式
- 饥饿模式中,不自旋,新来的协程直接进入sema休眠等待
- 饥饿模式中,被唤醒的协程直接获取锁
- 没有协程在队列中继续等待时,回到正常模式
锁竞争严重时,互斥锁进入饥饿模式
饥饿模式没有自旋等待,有利于公平
总结及使用经验
正常模式下,waiter 都是进入先入先出队列,被唤醒的 waiter 并不会直接持有锁,而是要和新来的 goroutine 进行竞争。新来的 goroutine 有先天的优势,它们正在 CPU 中运行,可能它们的数量还不少,所以,在高并发情况下,被唤醒的 waiter 可能比较悲剧地获取不到锁,这时,它会被插入到队列的前面。如果 waiter 获取不到锁的时间超过阈值 1 毫秒,那么,这个 Mutex 就进入到了饥饿模式。
在饥饿模式下,Mutex 的拥有者将直接把锁交给队列最前面的 waiter。新来的 goroutine 不会尝试获取锁,即使看起来锁没有被持有,它也不会去抢,也不会 spin,它会乖乖地加入到等待队列的尾部。
使用经验
- 减少锁的使用时间
- 在关键阶段加锁
- 善用defer 确保锁的释放
Mutex 错误使用场景
- Lock,Unlock非成对出现
- Copy 已经使用对mutex go vet工具检测
- 不可重入
- 死锁
RWMutex
读写锁,写优先
1type RWMutex struct {
2 w Mutex // held if there are pending writers 互斥锁作为写锁,加写锁才用的
3 writerSem uint32 // semaphore for writers to wait for completing readers 作为写协程队列
4 readerSem uint32 // semaphore for readers to wait for completing writers 作为读协程队列
5 readerCount int32 // number of pending readers 正直:正在读的协程 负值:加了写锁
6 readerWait int32 // number of departing readers 写锁加锁前要等待多少个读协程的个数
7}
3个等待队列,有3个sema,mutex中有一个
加写锁
- 先加mutex写锁,若已经被加写锁会阻塞等待, Mutex 陷入这个sema等待队列
- 加写锁成功,将readerCount变负值,阻塞读锁的获取。
- 计算需要等待多少个读协程释放
- 如果需要等待读锁释放,写入writerSem
解写锁
- 将readerCount变为正值,允许读锁的获取
- 释放在readerSem中的读协程
- 解锁mutex
加读锁 :readerCount > 0
- 没有写锁 ,readerCount=2,代表2个读协程在读
加读锁 : readerCount < 0
- 代表有写锁 加入readSem队列 readerCount = readerCount +1
加读锁总结
- 将给readerCount 无脑加1
- 当readerCount 是正数,加锁成功
- 如果readerCount是负数 ,说明被加了写锁,写入readSem
解除读锁
- 给readerCount 无脑-1
- 当readerCount 是正数,解锁成功
- 如果readerCount是负数,说明有写锁在排队
- 如果自己是readerWait的最后一个,唤醒写协程
使用经验
- rw 锁适合读多写少的场景,减少锁冲突
读写锁总结
- Mutex用来写协程之间互斥等待
- 读协程使用readerSem等待写锁的释放
- 写协程使用writeSem等待读锁的释放
- readerCount记录读协程的个数(正在读和想读的个数)
- readerWait 写协程加锁前要等待多少个读协程释放的个数
waitGroup
一个(组)协程 需要等待另一组协程完成
被等待协程个数、sema锁、等待协程个数
1// A WaitGroup must not be copied after first use.
2type WaitGroup struct {
3 noCopy noCopy // noCopy 的辅助字段,主要就是辅助 vet 工具检查是否通过 copy 赋值这个 WaitGroup 实例。
4
5 // 64-bit value: high 32 bits are counter, low 32 bits are waiter count.
6 // 64-bit atomic operations require 64-bit alignment, but 32-bit
7 // compilers do not ensure it. So we allocate 12 bytes and then use
8 // the aligned 8 bytes in them as state, and the other 4 as storage
9 // for the sema.
10 state1 [3]uint32
11}
noCopy 的辅助字段,主要就是辅助 vet 工具检查是否通过 copy 赋值这个 WaitGroup 实例。
waiter 有多少个协程等待运行, 放在sema 平衡二叉树队列
counter 有多少个协程在运行 (被等待协程), 运行完这些协程后,上面的waiter会被唤醒
sema 装载 等待协程
64位整数的原子操作要求整数的地址是 64 位对齐的,针对 64 位和 32 位环境的 state 字段的组成是不一样的。
在 64 位环境下,state1 的第一个元素是 waiter 数,第二个元素是 WaitGroup 的计数值,第三个元素是信号量。
在 32 位环境下,如果 state1 不是 64 位对齐的地址,那么 state1 的第一个元素是信号量,后两个元素分别是 waiter 数和计数值。
Wait()
- 如果被等待协程没了。直接返回
- 否则,waiter加1,陷入sema
1// Wait blocks until the WaitGroup counter is zero.
2func (wg *WaitGroup) Wait() {
3 statep, semap := wg.state() // statep 就是 count+waiter
4 if race.Enabled {
5 _ = *statep // trigger nil deref early
6 race.Disable()
7 }
8 for {
9 state := atomic.LoadUint64(statep)
10 v := int32(state >> 32) //拿到 counter
11 w := uint32(state) //拿到waiter
12
13 if v == 0 {
14 // Counter is 0, no need to wait. 被等待协程数是0 ,不需要等待
15 if race.Enabled {
16 race.Enable()
17 race.Acquire(unsafe.Pointer(wg))
18 }
19 return
20 }
21 // Increment waiters count.
22 if atomic.CompareAndSwapUint64(statep, state, state+1) {
23 if race.Enabled && w == 0 {
24 // Wait must be synchronized with the first Add.
25 // Need to model this is as a write to race with the read in Add.
26 // As a consequence, can do the write only for the first waiter,
27 // otherwise concurrent Waits will race with each other.
28 race.Write(unsafe.Pointer(semap))
29 }
30 runtime_Semacquire(semap)
31 if *statep != 0 {
32 panic("sync: WaitGroup is reused before previous Wait has returned")
33 }
34 if race.Enabled {
35 race.Enable()
36 race.Acquire(unsafe.Pointer(wg))
37 }
38 return
39 }
40 }
41}
Done()
被等待协程
- 给被等待协程counter -1
- 通过Add(-1) 实现
Add()
- Add Counter 可以是减
- 被等待协程没做完,或者没人在等待,返回
- 被等待协程都做完了,且有人在等待,唤醒所有sema中的协程
waitGroup 实现了一组协程等待另一组协程
等待的协程陷入sema并记录个数
被等待的协程计数归零时,唤醒所有sema中的协程
sync.Once
让代码执行一次 ?
思路1: Atomic
- 做法cas 改值 ,成功就做
- 优点:算法非常简单
- 问题:多个协程竞争cas改值会造成性能下降
思路2: mutex
争抢一个mutex,抢不到的陷入sema休眠
抢到的执行代码,改值,释放锁
其他协程唤醒后判断值已经修改,直接返回
1package sync
2
3import (
4 "sync/atomic"
5)
6
7// Once is an object that will perform exactly one action.
8type Once struct {
9 // done indicates whether the action has been performed.
10 // It is first in the struct because it is used in the hot path.
11 // The hot path is inlined at every call site.
12 // Placing done first allows more compact instructions on some architectures (amd64/x86),
13 // and fewer instructions (to calculate offset) on other architectures.
14 done uint32
15 m Mutex
16}
17
18// Do calls the function f if and only if Do is being called for the
19// first time for this instance of Once. In other words, given
20// var once Once
21// if once.Do(f) is called multiple times, only the first call will invoke f,
22// even if f has a different value in each invocation. A new instance of
23// Once is required for each function to execute.
24//
25// Do is intended for initialization that must be run exactly once. Since f
26// is niladic, it may be necessary to use a function literal to capture the
27// arguments to a function to be invoked by Do:
28// config.once.Do(func() { config.init(filename) })
29//
30// Because no call to Do returns until the one call to f returns, if f causes
31// Do to be called, it will deadlock.
32//
33// If f panics, Do considers it to have returned; future calls of Do return
34// without calling f.
35//
36func (o *Once) Do(f func()) {
37 // Note: Here is an incorrect implementation of Do:
38 //
39 // if atomic.CompareAndSwapUint32(&o.done, 0, 1) {
40 // f()
41 // }
42 //
43 // Do guarantees that when it returns, f has finished.
44 // This implementation would not implement that guarantee:
45 // given two simultaneous calls, the winner of the cas would
46 // call f, and the second would return immediately, without
47 // waiting for the first's call to f to complete.
48 // This is why the slow path falls back to a mutex, and why
49 // the atomic.StoreUint32 must be delayed until after f returns.
50
51 if atomic.LoadUint32(&o.done) == 0 {
52 // Outlined slow-path to allow inlining of the fast-path.
53 o.doSlow(f)
54 }
55}
56
57func (o *Once) doSlow(f func()) {
58 o.m.Lock()
59 defer o.m.Unlock()
60 // double check 都进入doSlow 可能有并发问题。 o.Done 被改了 导致重复执行f() 。
61 if o.done == 0 {
62 defer atomic.StoreUint32(&o.done, 1)
63 f()
64}
sync.Once做法
- 先判断是否已经改值
- 没改,尝试获取锁
- 获取到锁的协程执行业务,改值,解锁
- 冲突协程唤醒后直接返回
double check 都进入doSlow 可能有并发问题,导致重复执行f() 。
如何排查锁异常问题
锁拷贝问题
- 锁拷贝可能导致的死锁问题
- 使用vet 工具可以检测锁拷贝问题
- vet还能检测可能的bug 或者可以的构造
race竞争检测
- 发现隐含的数据竞争问题
- 可能是加锁的建议
- 可能是bug的提醒
go-deadlock 检测可能的死锁
sync.Pool
sync.Pool 临时对象池 (对象缓存)
对象获得
- 尝试从私有对象获取
- 私有对象不存在,尝试从当前processor的共享池获取
- 如果当前processor共享池也是空的,那么从其他processor的共享池获取
- 如果所有子池都是空的,那么就用用户指定的new函数产生一个新的对象返回
- 私有对象 协程安全,共享池协程不安全
Sync.Pool对象的放回
- 如果私有对象不存在则保存私有对象
- 如果私有对象存在,放入当前Processor子池的共享池
sync.Pool结构,local,victim核心字段
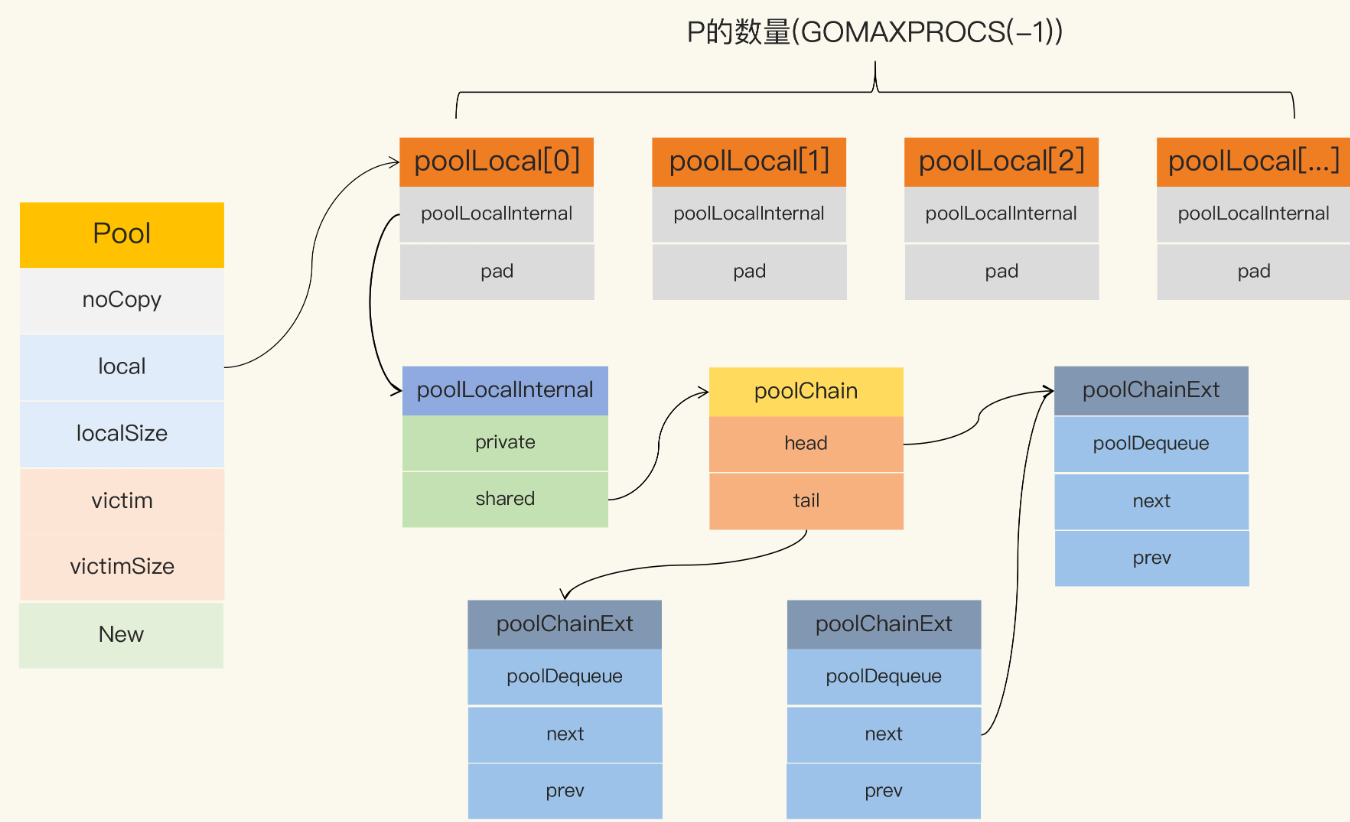
Pool 最重要的两个字段是 local 和 victim,因为它们两个主要用来存储空闲的元素。
每次垃圾回收的时候,Pool 会把 victim 中的对象移除,然后把 local 的数据给 victim,这样的话,local 就会被清空,而 victim 就像一个垃圾分拣站,里面的东西可能会被当做垃圾丢弃了,但是里面有用的东西也可能被捡回来重新使用。
victim 中的元素如果被 Get 取走,那么这个元素就很幸运,因为它又“活”过来了。但是,如果这个时候 Get 的并发不是很大,元素没有被 Get 取走,那么就会被移除掉,因为没有别人引用它的话,就会被垃圾回收掉。
1
2func poolCleanup() {
3 // This function is called with the world stopped, at the beginning of a garbage collection.
4 // It must not allocate and probably should not call any runtime functions.
5
6 // Because the world is stopped, no pool user can be in a
7 // pinned section (in effect, this has all Ps pinned).
8
9 // Drop victim caches from all pools.
10
11 //丢弃当前victim ,stop the world 不用加锁
12 for _, p := range oldPools {
13 p.victim = nil
14 p.victimSize = 0
15 }
16
17 // Move primary cache to victim cache.
18 //将local 复制给 victim,原来的local置成nil
19 for _, p := range allPools {
20 p.victim = p.local
21 p.victimSize = p.localSize
22 p.local = nil
23 p.localSize = 0
24 }
25
26 // The pools with non-empty primary caches now have non-empty
27 // victim caches and no pools have primary caches.
28 oldPools, allPools = allPools, nil
29}
poolLocalInternal
poolLocalInternal 包含2个字段 private,shared
1type poolLocalInternal struct {
2 private any // Can be used only by the respective P.
3 shared poolChain // Local P can pushHead/popHead; any P can popTail.
4}
private,代表一个缓存的元素,而且只能由相应的一个 P 存取。因为一个 P 同时只能执行一个 goroutine,所以不会有并发的问题。
shared,可以由任意的 P 访问,但是只有本地的 P 才能 pushHead/popHead,其它 P 可以 popTail,相当于只有一个本地的 P 作为生产者(Producer),多个 P 作为消费者(Consumer),它是使用一个 local-free 的 queue 列表实现的
Get实现
1func (p *Pool) Get() any {
2 if race.Enabled {
3 race.Disable()
4 }
5 //把当前groutine 固定在当前P上
6 l, pid := p.pin()
7 x := l.private //优先从 private 字段取,快速
8 l.private = nil
9 if x == nil { // private 不存在
10 // Try to pop the head of the local shard. We prefer
11 // the head over the tail for temporal locality of
12 // reuse.
13 //从当前local shared 弹出一个,注意从head 读取并移除
14 x, _ = l.shared.popHead()
15 if x == nil {
16 //如果没有 取其他P上偷一个
17 x = p.getSlow(pid)
18 }
19 }
20 runtime_procUnpin()
21 if race.Enabled {
22 race.Enable()
23 if x != nil {
24 race.Acquire(poolRaceAddr(x))
25 }
26 }
27
28 //都没有拿到,尝试New 函数去生产一个新的
29 if x == nil && p.New != nil {
30 x = p.New()
31 }
32 return x
33}
1func (p *Pool) getSlow(pid int) any {
2 // See the comment in pin regarding ordering of the loads.
3 size := runtime_LoadAcquintptr(&p.localSize) // load-acquire
4 locals := p.local // load-consume
5 // Try to steal one element from other procs.
6
7 //从其他procs 偷取一个元素
8 for i := 0; i < int(size); i++ {
9 l := indexLocal(locals, (pid+i+1)%int(size))
10 if x, _ := l.shared.popTail(); x != nil {
11 return x
12 }
13 }
14
15 // Try the victim cache. We do this after attempting to steal
16 // from all primary caches because we want objects in the
17 // victim cache to age out if at all possible.
18
19 //如果其他procs 没有可用元素,尝试从 victim 中获取
20 size = atomic.LoadUintptr(&p.victimSize)
21 if uintptr(pid) >= size {
22 return nil
23 }
24 locals = p.victim
25 l := indexLocal(locals, pid)
26 if x := l.private; x != nil { //同样的逻辑 先从 victim的local private中获取
27 l.private = nil
28 return x
29 }
30 for i := 0; i < int(size); i++ { //从victim 其他proc 偷取
31 l := indexLocal(locals, (pid+i)%int(size))
32 if x, _ := l.shared.popTail(); x != nil {
33 return x
34 }
35 }
36
37 // Mark the victim cache as empty for future gets don't bother
38 // with it.
39 //标记 这个victim为空,以后查找快速跳过
40 atomic.StoreUintptr(&p.victimSize, 0)
41
42 return nil
Put实现
1// Put adds x to the pool.
2func (p *Pool) Put(x any) {
3 if x == nil { // nil 直接丢弃
4 return
5 }
6 if race.Enabled {
7 if fastrandn(4) == 0 {
8 // Randomly drop x on floor.
9 return
10 }
11 race.ReleaseMerge(poolRaceAddr(x))
12 race.Disable()
13 }
14 l, _ := p.pin()
15 if l.private == nil { //如果本地private 为空, 则直接设置这个指即可
16 l.private = x
17 x = nil
18 }
19 if x != nil { // 否则加入到本地队列
20 l.shared.pushHead(x)
21 }
22 runtime_procUnpin()
23 if race.Enabled {
24 race.Enable()
25 }
26}
sync.Cond
Go 标准库提供 Cond 原语的目的是,为等待 / 通知场景下的并发问题提供支持。Cond 通常应用于等待某个条件的一组 goroutine,等条件变为 true 的时候,其中一个 goroutine 或者所有的 goroutine 都会被唤醒执行。
对应的有3个常用方法,Wait,Signal,Broadcast。
11) func (c *Cond) Wait() wait 之前加上锁
2该函数的作用可归纳为如下三点:
3a) 阻塞等待条件变量满足
4b) 释放已掌握的互斥锁相当于cond.L.Unlock()。 注意:两步为一个原子操作。(原子操作,一起获得cpu )
5c) 当被唤醒时,Wait()函数返回时,解除阻塞并重新获取互斥锁。相当于cond.L.Lock()
6
72) func (c *Cond) Signal()
8 单发通知,给一个正等待(阻塞)在该条件变量上的goroutine(线程)发送通知。
93) func (c *Cond) Broadcast()
10广播通知,给正在等待(阻塞)在该条件变量上的所有goroutine(线程)发送通知。
条件变量的Wait方法主要做了四件事。
- 把调用它的 goroutine(也就是当前的 goroutine)加入到当前条件变量的通知队列中。
- 解锁当前的条件变量基于的那个互斥锁。
- 让当前的 goroutine 处于等待状态,等到通知到来时再决定是否唤醒它。此时,这个 goroutine 就会阻塞在调用这个
Wait方法的那行代码上。 - 如果通知到来并且决定唤醒这个 goroutine,那么就在唤醒它之后重新锁定当前条件变量基于的互斥锁。自此之后,当前的 goroutine 就会继续执行后面的代码了。
1
2type Cond struct {
3 noCopy noCopy
4
5 // 当观察或者修改等待条件的时候需要加锁
6 L Locker
7
8 // 等待队列
9 notify notifyList
10 checker copyChecker
11}
12
13func NewCond(l Locker) *Cond {
14 return &Cond{L: l}
15}
16
17func (c *Cond) Wait() {
18 c.checker.check()
19 // 增加到等待队列中
20 t := runtime_notifyListAdd(&c.notify)
21 c.L.Unlock()
22 // 阻塞休眠直到被唤醒
23 runtime_notifyListWait(&c.notify, t)
24 c.L.Lock()
25}
26
27func (c *Cond) Signal() {
28 c.checker.check()
29 runtime_notifyListNotifyOne(&c.notify)
30}
31
32func (c *Cond) Broadcast() {
33 c.checker.check()
34 runtime_notifyListNotifyAll(&c.notify)
35}
links
- 极客时间《go并发编程实战课》
- 我的编程编程代码总结